
















Our TechTalkThursday #20 took place on the 2nd of May 2024 at 6PM. We were happy to welcome two external speakers and one 9er who gave a speech. There were around 30 people attending the event, many of them Nine employees, but also some speakers’ guests and external attendees interested in the subjects of centralised search engines, retrieval augmented generation and AI.
Apart from the fact that we celebrated a small anniversary – the 20th event of our TechTalkThursday series – we were also very proud to show off our very own beer, «Deploibroi». This beer was created in partnership with Renuo AG, our deplo.io partner, and Braugenossenschaft Gsöff in Zurich. The beer (and the free snacks) were very well received by everyone.
Thomas Hug, founder and CEO of Nine, started the event off with a short introduction, presenting the speakers and their topics. The three speakers were Kevin Ferranti, Software Engineer at Nine, Griffin White, founder of GWCustom, and Vito Cudemo, founder of and Software Engineer at Solity.
Scouter: A Centralised Search Engine
Kevin talked about the development and functionality of Scouter, a centralised search engine designed for ticketing systems. This project also served as his bachelor’s thesis.
Why Scouter?
Scouter aims to address two primary areas: archiving and search functionality within IT support systems. To improve these, its goal is to streamline data access and enhance the efficiency of solving IT support issues by leveraging past tickets and interactions.
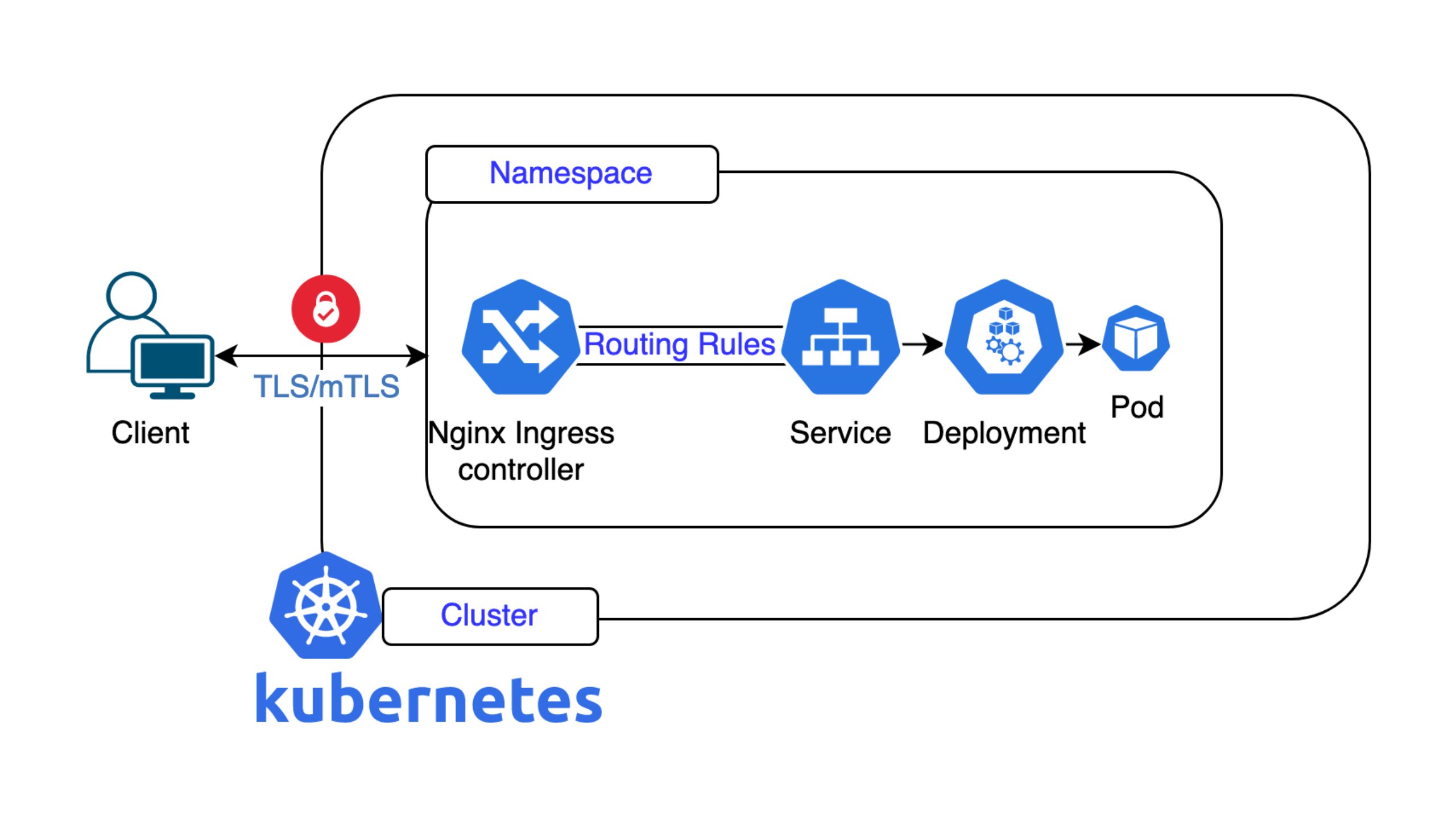
Kevin explains that the primary motivation for developing Scouter was to replace the existing practice of running multiple ticketing systems merely for data access. This method is inefficient and costly. By centralising data in Scouter, the integrity and immutability of archived data is improved, preventing unauthorised changes and preserving historical context.
Archiving
The archiving process within Scouter involves creating database dumps of ticketing systems like OTRS and Jira. These dumps are stored on a new database management system (DBMS) on a target server. The data in these dumps are read-only to maintain integrity. This method retains the semantic context and metadata, ensuring that the data remains meaningful and understandable.
Benefits of Database Dumps
- Semantic Context: Retains table structures and relationships, preserving the meaning and usability of the data.
- Simple Format: Uses SQL statements, which are human-readable and easy to manage.
- Independence: SQL statements are independent of the storage medium and only require a compatible DBMS like MySQL or Postgres.
- Comprehensive Backup: Ensures that all necessary data is archived and can be restored on demand.
Search Engine Functionality
Scouter’s search engine is tailored to enterprise needs, offering features that are critical for effective IT support. These include:
- Relevance Ranking: Search results are ranked based on relevance, with recent tickets given higher priority.
- User Annotations: Users can annotate and rate tickets, enhancing the search engine’s ability to provide useful results over time.
- Hit Highlighting: Key terms in search results are highlighted, making it easier to identify relevant information.
- Advanced Search Filters: Conditional operators, wildcard search, fuzzy search, and other advanced search functionalities are supported through Apache Solr integration.
Technologies Used
The application is built using Ruby on Rails and integrates various technologies to achieve its objectives:
- Apache Solr: For search functionalities
- GitLab: To retrieve context information via REST API
- Postgres: As the DBMS for storing annotations and rankings
Pros and Cons
Kevin presents the pros and cons of Scouter as follows:
- Pros:
- Centralised access to historical tickets
- Improved data integrity and preservation
- Enhanced search functionalities tailored to IT support needs
- Cons:
- Some features like faceted search and replication are not fully implemented
- Potential challenges in technology interchangeability and scalability
Future Steps
The next steps for Scouter include:
- Implementing additional features like faceted search
- Exploring replication solutions for better data redundancy
- Continuous evaluation and improvement based on user feedback and technological advancements
Retrieval-Augmented Generation: The Next Generation of Information Search
Griffin’s presentation focused on advancements and applications in AI-powered searchable systems. The speaker delved into the development and deployment of high-bandwidth interfaces for indexing knowledge, specifically tailored to IT professionals. These systems are designed to index a multitude of sites simultaneously, facilitating efficient knowledge management and retrieval.
Highlights
A key feature highlighted is the ability of the system to handle custom deployments, accommodating various organisational needs. It supports local and custom deployments, offering a scalable solution for indexing large volumes of data. With the integration of an API key, users can index thousands of documents, providing a robust and flexible interface for large-scale information management.
The presentation emphasised the evolving nature of knowledge and the necessity for systems that can adapt to these changes. Griffin pointed out that knowledge is continually being updated, necessitating a backend that reflects these modifications. The aim is to create a central repository that can be easily searched, reducing the time spent by IT professionals searching for information across multiple locations. This centralisation of information is intended to streamline workflows and improve efficiency.
Evolution of Search Engines
The speaker also discusses the historical evolution of search systems, contrasting traditional methods like library card catalogues with modern AI-powered search engines. This comparison underscores the advancements in search technology and the increased efficiency and accessibility provided by contemporary systems.
A demonstration of the system’s capabilities showcases its user-friendly interface and powerful search functionalities. Users can manage knowledge through conversations, annotations, and linking related tickets. The system is designed to highlight relevant context, such as changes in code repositories like GitLab, providing users with comprehensive information at their fingertips.
Technical Details
The presentation further detailed the technical aspects of the system, including the use of Ruby on Rails for the main application, and integration with Apache Solr for indexing. The system also supports database management systems used by popular ticketing platforms like Jira and OTRS. The speaker explained that efficient data archiving was a significant part of the development process, with database dumps being identified as the best solution for archiving.
Griffin provided an insightful overview of an advanced AI-powered search system designed to enhance knowledge management and retrieval for IT professionals. The system’s ability to index large volumes of data, adapt to changing knowledge, and provide a centralised searchable repository marks a significant step forward in the field of information management.
AI & LLM in Business Use and Short Demo with docs.nine.ch
Unfortunately, Vito’s speech wasn’t to his complete satisfaction and contained some information that he only wanted to share with those physically present at the event. Therefore, we cannot show you any recording or summary of his speech. But he promised to be back as soon as possible with «a professional speech and a product that’s better prepared to be shown publicly» – his own words.
Want to stay up to date?
Subscribe to our YouTube channel and regularly visit our website’s blog.