











When talking to people about migrating their applications to Kubernetes, there are often questions about storage:
- Will the data remain in Switzerland? (data locality)
- Is the data encrypted at rest?
- Is there any in-transit encryption?
- Would it be possible to provide ‘insert big number here’ of storage space?
One thing that is often overlooked is how to access and store data in a multi-node Kubernetes cluster and which infrastructure will be needed for this. As we have several options, I’d like to shed some light on this topic and explain the differences.
Why Do We Have to Choose?
Often, applications are run directly on a single server (VM or bare metal), as the computing power of one machine is just enough for this use case. If there are other applications to run, they are also operated either on the same machine or on one other single instance. Storing data is easy as the application can just read and write to a local disk. This type of architecture most often emerges due to legacy and economic reasons, as there is no need for a load balancer or complicated cluster setup.
To consolidate all those applications in a Kubernetes cluster (to unify the deployment experience, provide more error tolerance, etc.), most of the applications should support one thing: running instances in a distributed manner with multiple replicas (on different nodes).
This is because in a Kubernetes cluster, nodes are very dynamic. A node can go down at any point in time (due to unexpected failure, maintenance, cluster-autoscaling, etc). For example, when we run cluster upgrades on our NKE clusters, we completely replace the nodes of every cluster instead of updating the software packages of the operating system on each instance. In case of a node failure, Kubernetes takes care of moving running applications to different servers in the cluster. However, this might take a few minutes, and having just one instance of the application running might result in short disruptions. These disruptions can add up in a maintenance window, as every node needs to be replaced. Running the application on more than one node in parallel solves this issue and is one of our recommended best practices.
There is one challenge though. If every application instance only stores data locally on the node where it runs, other instances won’t have access to that data as they are running on different machines. Often, web applications store user-uploaded data (PDFs, images, etc). This data then needs to be accessible by all application replicas. Besides our applications, which need to be ready to work in a distributed environment, we might therefore also need a storage system which can be accessed by distributed clients.
What Can We Choose from?
Based on the last paragraph, storage system access in Kubernetes can be divided into 2 types:
- read-write-once (RWO)
- read-write-many (RWX)
The difference is easy to explain. If a storage location can only be accessed by one ‘writer’ (an application which wants to write or delete data) on one node at one point in time, the access type is called read-write-once. It might be that other applications running on different nodes can have read-only access to the storage space, but this depends on the system in use.
If multiple writers (on different nodes) need to make changes to the data, we need a storage system which supports read-write-many access.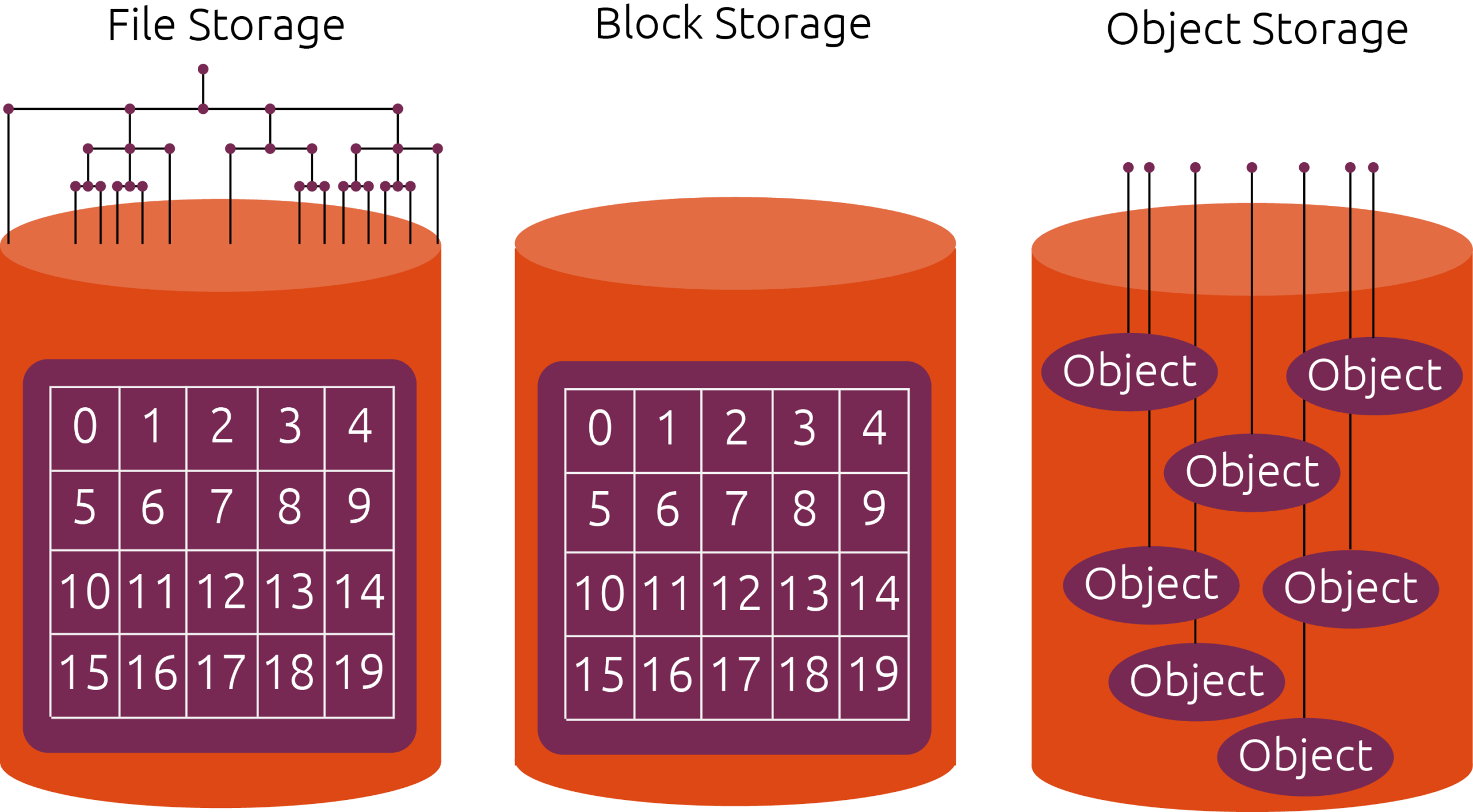
Image source: Canonical
Block Storage
Whenever a node accesses raw partitions or raw disks, we actually refer to block storage (as disk blocks are accessed directly). Usually we put a filesystem on top of the raw blocks and expose it to applications running on that one node (so block storage is a representative of the read-write-once access category).
You have a single replica application (for example a development Postgres database pod) which needs its own space for storage? Choose block storage.
There are 2 variants of this:
- node local block storage (aka a disk attached to a specific node)
- remote block storage which you can access via iSCSI, fibre channel, etc.
Remote block storage can often be attached to a different node in case of a failure or maintenance, so it provides machine fault tolerance. Persistent node local block storage however is bound to one specific node, but might make sense when having bare metal servers being part of the Kubernetes cluster and your application needs very fast access to the storage space. However, all applications using persistent node local storage are bound to that one server and in case of a failure, your application won’t be able to run. Maybe fault tolerance can be achieved in the application itself in such a case (the software itself communicates with other replicas and can self-heal in case of failures), but in general, we recommend using a fast remote block storage as it most often allows for more flexibility (also in terms of storage expansion). For example, all our NKE clusters are build up on virtual machines and support a fast remote block storage by default, but no persistent local node storage.
There are also ephemeral node local storage solutions like Kubernetes emptyDir or Googles local SSD feature for GKE clusters which can be used as scratch space or temporary storage.
Typically, you pay for the amount of block storage which you requested and not for how much you have already used of it.
File Storage
In contrast to block storage, file storage (as the name implies) allows you to share files with multiple distributed clients by exposing a shared file system. Applications running on Kubernetes can access those files as if they were local files. As almost every programming language allows access to files, using file storage is most often the first choice when needing read-write-many access. Solutions like NFS, CIFS, CephFS or GlusterFS implement file storage access.
Files are structured in a directory tree which can be quite deeply nested. Every file has a payload (the real data of the file), but additionally needs metadata to be stored (access permissions, file type, etc). As multiple distributed clients can access the filesystem in parallel, there need to be locking mechanisms additionally in place which guarantee a consistent view of every client. This is handled differently by the various implementations (and also changed over time in NFS implementations, for example). Without going too deeply into the technical details, file storage systems most often provide a lower performance compared to block storage, but they also provide the possibility of read-write-many access which may be a requirement when using Kubernetes. Additionally, not all file storage implementations provide full POSIX compatibility.
From the perspective of an infrastructure provider, it is not so easy to provide and operate dynamically provisioned file storage in a Kubernetes environment. We used to manage some in-cluster NFS instances ourselves, but we ran into issues during maintenance times, when all nodes are being replaced. Clients sometimes stalled and pods didn’t get started. Additionally, NFS and CIFS are long-standing solutions which might not fit into today’s dynamic environments.
For example, NFSv3 authenticates clients based on IP addresses which are mostly ephemeral in a Kubernetes cluster. NFSv4 can securely authenticate clients, but a Kerberos infrastructure is needed for this. CIFS supports some nice features, but also ships Windows-specific things like printer sharing which is not really needed in a Kubernetes environment. Additionally, there are currently 2 NFS related kubernetes-sigs projects, but none for CIFS. CephFS is really promising in terms of features and scalability, but it also is complex to operate (although rook improved the situation). We also used early versions of GlusterFS when still operating Openshift clusters some years ago, but we faced quite a few consistency and availability problems back then.
Providing automatic backups and restore possibilities for file storage solutions in a Kubernetes environment can be a further challenge.
Overall, file storage solutions come with a higher price tag, as operating them in an automated way might need a substantial engineering effort. We provide read-write-many storage space in our NKE clusters which is backed by a NFS solution from our compute infrastructure provider.
Object Storage
Besides the aforementioned file storage solutions, object storage has got more and more popular as it also allows read-write-many access. Instead of files, data is put into objects which have a unique ID in a flat namespace (bucket). Each object also has metadata attached (which allows for searching).
Accessing objects works via HTTP based protocols, with Amazon’s S3 being the most popular one (as they invented it). This kind of access makes it very different from file-storage-based solutions. There is no shared filesystem mounted and passed into the container anymore. The underlying operating system or the cluster orchestrator is not involved for data access. Instead, the application itself accesses the object storage system via libraries. This allows for great flexibility, but might also imply changes to the source code of the application. These code changes also what block some applications from using object storage. It would just be too much work to implement it.
However, once the application can make use of object storage solutions, there are some great features to benefit from. Here are some examples:
- pay-what-you-use model: only the space which you use gets charged (plus fees for API calls and/or bandwidth)
- virtually endless space to use (no pre-provisioning of space needed)
- various policy settings allow control over access permissions for buckets and the objects within them on a per user (e.g. ‘access key’) basis
- write-once-read-many buckets (WORM): data which was written once, can not be deleted/overwritten anymore. Policies can make sure that data gets deleted automatically after a certain amount of time.
- access data from anywhere: buckets and objects can normally be accessed from all over the world, no matter where your application is running. A deployed file storage solution might not be accessible from outside your Kubernetes cluster.
- usage of HTTPS provides encryption-in-transit
- mostly provider independent: you can just switch to use a different provider, given the object storage protocol is the same (and you don’t make use of very provider specific features).
But there are also some drawbacks with object storage and its implementations. Objects can only be written as a whole. This means you can’t open an object to append to it (as you can do when using file storage). You would need to download the whole object, append your data in the application and upload all the data again. Accessing object storage is also often slower than file storage, so applications which need high-speed access to data might need to use some caching or fallback to a file storage solution. To speed up access to object storage systems, requests should be made in parallel where possible. There are also differences in the feature set (and quality) of object storage solutions which allow access via the same protocol.
For our customers we provide a S3 compatible object storage solution hosted in Swiss data centres.
So What Should I Use in The End?
If your application just consists of a single replica and only needs read-write-once access, fast remote block storage should be your choice. It allows for fail-over to a different node in case of a failure and provides good performance.
If you need read-write-many access, we favour the use of object storage over file storage (if your use case allows for it). Even if your application would need some changes to support object storage, it might be worth it in the long run. Using objects just allows for more flexibility and might also provide more features.
Featured image source: Intelligent CIO