











Our TechTalkThursday #22 took place on the 5th of Dezember 2024 at 6PM in our office. We were happy to welcome two external speakers and one 9er who gave a speech. There were around 40 people attending the event, some of them Nine employees, but also some speakers’ guests and many external attendees interested in the subjects of Kubernetes in hospitals, building generative AI-powered apps with MongoDB Atlas and service mesh.
Apart from the fact that we live-streamed the event on YouTube, we were also very proud to show off our second Deploio-branded beer, «Deploibroi 2.0». After the success of the first beer – created in partnership with Renuo AG, our Deploio partner, and Braugenossenschaft Gsöff in Zurich –, the second version also didn’t disappoint: The beer was very well received by everyone.
Thomas Hug, founder and CEO of Nine, started the event off with a short introduction, presenting the speakers and their topics. The three speakers were Dan Acristinii, Product Manager Edge Infrastructure at Roche, Daniel Lorch, Senior Solutions Architect at MongoDB, and Sebastian Nickel, Senior Engineer Platform at Nine.
Kubernetes in Hospitals: How Roche Manages Edge Clusters Worldwide
Dan’s talk focused on Roche’s use of Kubernetes in healthcare environments, particularly hospitals and laboratories. He explained how Roche uses edge computing to manage medical diagnostics and ensures efficient data processing while maintaining compliance with healthcare regulations.
He talked about the Navify platform, Roche’s internal platform for digital healthcare solutions, supporting diagnostic processes in labs and hospitals. It processes data locally at edge clusters instead of relying heavily on the cloud, minimizing latency, bandwidth issues, and regulatory concerns. Dan also mentioned edge computing in labs and hospitals, where labs deploy small computers not directly connected to diagnostic instruments but responsible for processing and monitoring instrument data. He pointed out that edge clusters enable secure and efficient data handling, avoiding dependency on direct instrument updates, which require rigorous medical compliance.
Then, he made a deep dive into the technical infrastructure, where Roche employs Kubernetes for its cloud-native architecture. Edge clusters are managed globally through AWS-hosted services, with updates pushed via a streamlined process. Talos OS, a Kubernetes-specific operating system with no shell access, is used to enhance security and functionality. And Cilium is leveraged for advanced networking, including traffic control and secure API access, reducing the burden on application teams to configure firewalls or manage connectivity directly. Dan also mentioned that local data processing at Roche ensures data privacy and avoids compliance complications with moving sensitive patient data to the cloud. Edge computing also addresses bandwidth limitations in certain areas and provides lower latency for critical medical operations.
He then talked about some challenges and their solutions. For example, some deployments must operate in air-gapped environments or with limited connectivity, requiring unique networking and orchestration solutions. Also, Roche developed its own tools to handle the limitations of Rancher, enabling the management of numerous disconnected Kubernetes clusters worldwide. According to Dan, Roche has contributed to open-source projects, such as enterprise-grade Cilium features. Terraform and other modern infrastructure-as-code tools play a crucial role in provisioning and maintaining edge clusters.
Dan concluded his speech by highlighting Roche’s broader push into digital products and software, which complements its pharmaceutical and diagnostics work. The architecture described exemplifies scalability, compliance, and innovation in healthcare technology.
Building Generative AI-powered Apps With MongoDB Atlas
Then, it was Daniel’s turn. He focused on MongoDB Atlas, vector search, and applications in AI-powered systems. He first introduced MongoDB and explained that it is a document-based database that stores information as structured documents, offering flexibility and speed compared to traditional relational databases. Atlas, MongoDB’s cloud-based platform, supports features like geospatial data, time-series management, full-text search, and integrations for distributed and synchronized environments.
Daniel then went on and said that Atlas facilitates the integration of large language models (LLMs) into AI-powered apps by storing and retrieving vector embeddings. These embeddings encode the meaning of unstructured data (e.g., text, images, audio) into vectors for efficient processing and querying. Furthermore, Vector search enables retrieving similar data points by comparing embeddings, making it useful for LLMs to generate context-aware answers. And the Retrieval-Augmented Generation (RAG) approach combines pre-trained LLMs with personalized, context-specific data for enhanced accuracy in answering user queries.
Daniel showcased a chatbot that uses MongoDB Atlas for vector-based queries to provide meaningful and relevant responses. The system ingests data from sources like sitemaps, processes it into vectors, and integrates it into prompts to generate answers with LLMs. The key advantages are that MongoDB’s schema flexibility allows for hybrid searches combining keyword and vector-based queries. Also, the platform supports advanced queries, enabling tailored AI applications in domains like customer service, personalized recommendations, and data analysis.
He concluded his talk with some words about tools and frameworks. He mainly said that MongoDB offers open-source frameworks for building chatbots and AI integrations with LLMs. These tools simplify the ingestion, indexing, and query processes, reducing setup time and enabling faster deployment of AI systems. In the end, Daniel showed some practical demonstrations, emphasizing the role of MongoDB Atlas in advancing AI application development through robust data management and integration with LLMs.
Service Mesh = Service Mess?
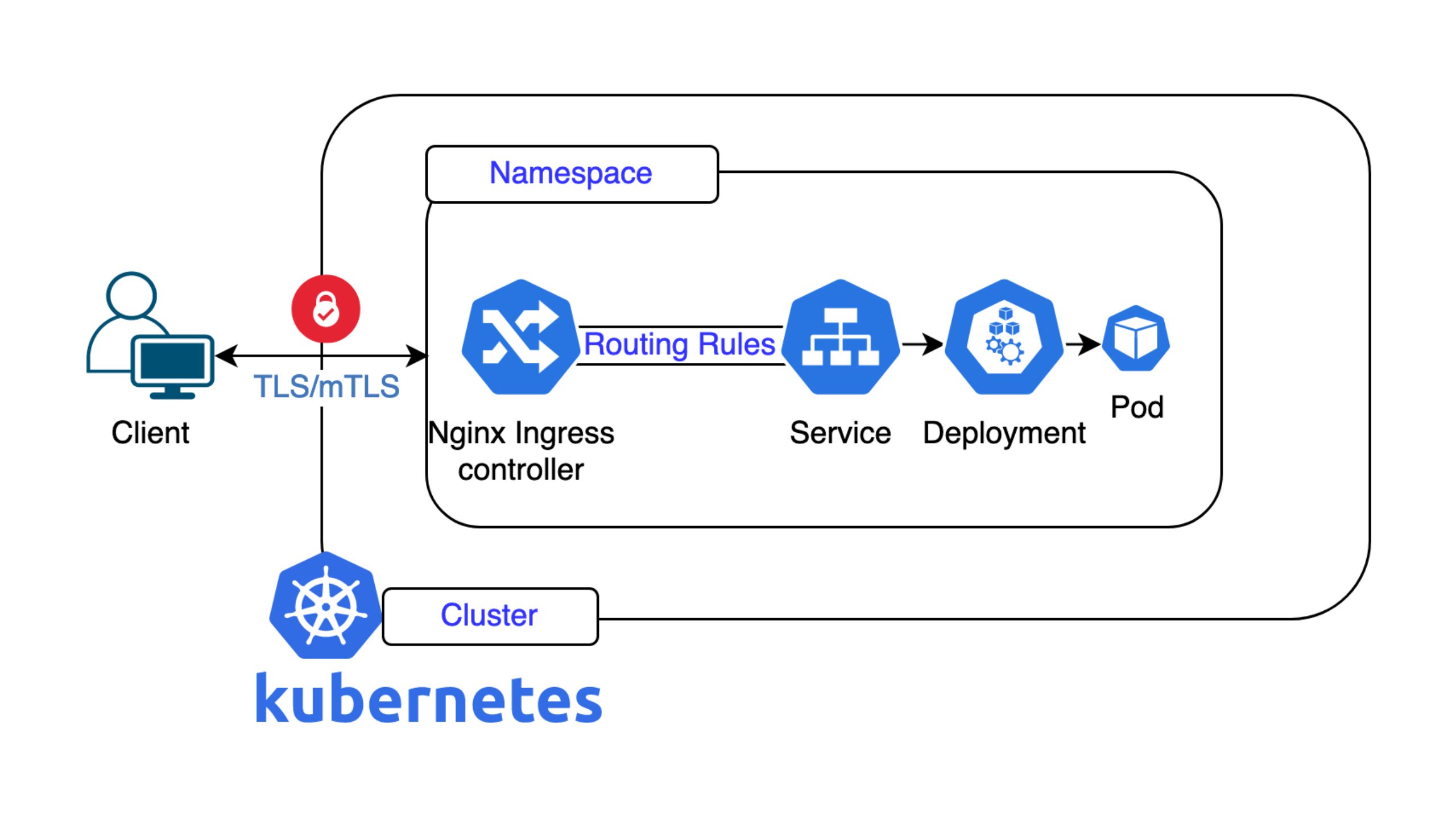
Nick’s presentation was the last one of the three at the TechTalkThursday #22. He focused on the challenges, solutions, and lessons learned in implementing service mesh for seamless connectivity between services in Kubernetes clusters and virtual machines (VMs). The talk highlighted the evolution of Nine’s approach to service mesh and the technical considerations involved.
The problem was that connecting services across Kubernetes clusters, VMs, and other systems was difficult due to issues like dynamic IP addresses, lack of encryption, and firewall limitations. Therefore, classical networking approaches such as static IP assignments or public IPs with dynamic firewall rules were insufficient.
The initial attempts for solving the problems started in 2021. Early evaluations of service mesh tools like Cilium External Workloads, Kilo, and Kuma revealed limitations:
- Cilium: Required extensive subnet management and didn’t fully meet their needs
- Kilo: WireGuard-based but relied on a leader pod, complicating automation
- Kuma: Provided multi-cluster support but had security and complexity concerns
The team abandoned these attempts due to high complexity and security limitations.
Two years later, a second attempt was made. Nine revisited the problem using Istio, a prominent service mesh solution. Istio was powerful but overly complex, with challenges in debugging and managing its configuration (e.g., handling identity and MTLS via Spiffy/Spire). And static egress IPs were introduced as a temporary workaround, allowing services to use fixed IPs for external connectivity.
During a third attempt in 2024, Nine explored Linkerd and Istio Ambient Mesh for sidecar-free, lightweight alternatives. Linkerd showed promise due to its simplicity, lack of a global control plane, and service mirroring capabilities but failed due to namespace conflicts. Istio Ambient Mesh reduced some complexity but was hindered by unclear documentation and issues with network policies.
Then, the breakthrough finally happened: Nine shifted to Tailscale, a WireGuard-based full-mesh networking solution with a central control server. Its advantages are numerous:
- Minimal configuration required for Kubernetes services
- Built-in DNS for seamless service discovery
- No additional IPv4 addresses needed, leveraging existing public IPs
- Limitations included compatibility issues with open-source alternatives like HeadScale
After years of experimenting with various service mesh technologies, Tailscale emerged as a simpler, effective solution for many use cases. However, the search for an ideal, long-term service mesh continues, balancing complexity, security, and functionality. In the end, Nick’s talk provided a candid overview of the iterative process, highlighting the value of persistence and adaptability in tackling technical challenges.
Want to Stay Up to Date?
Subscribe to our YouTube channel and regularly visit our website’s blog.