
















Our fourth and last TechTalkThursday in 2025 – it was number 26 of our event series – took place on the 2nd of December 2025 at 6PM in our office. It was the first time on a Tuesday, so TechTalkTuesday might be more appropriate. Anyway, we proudly welcomed three external speakers who all held captivating talks. There were many people attending the event on site, also some interested Nine employees, a few speakers’ guests and a lot of external attendees interested in the topics of the Nutanix Kubernetes Platform, RAM xor Downtime and Data Localization for Application Services at Cloudflare.
This TechTalkThursday was also live-streamed on our YouTube channel and we were happy to see some listeners also on that platform. As usual, Thomas Hug, our CEO and founder, started off the event with a short introduction, presenting the evening’s agenda, introducing the speakers and presenting the topics of their upcoming talks. This time, the three speakers were Patrick Jundt, Senior Systems Engineer MSP at Nutanix, Josua Schmid Engineer & Partner at Renuo, and Josip Stanić, Solutions Engineer at Cloudflare.
Nutanix Kubernetes Platform: Deep-Dive
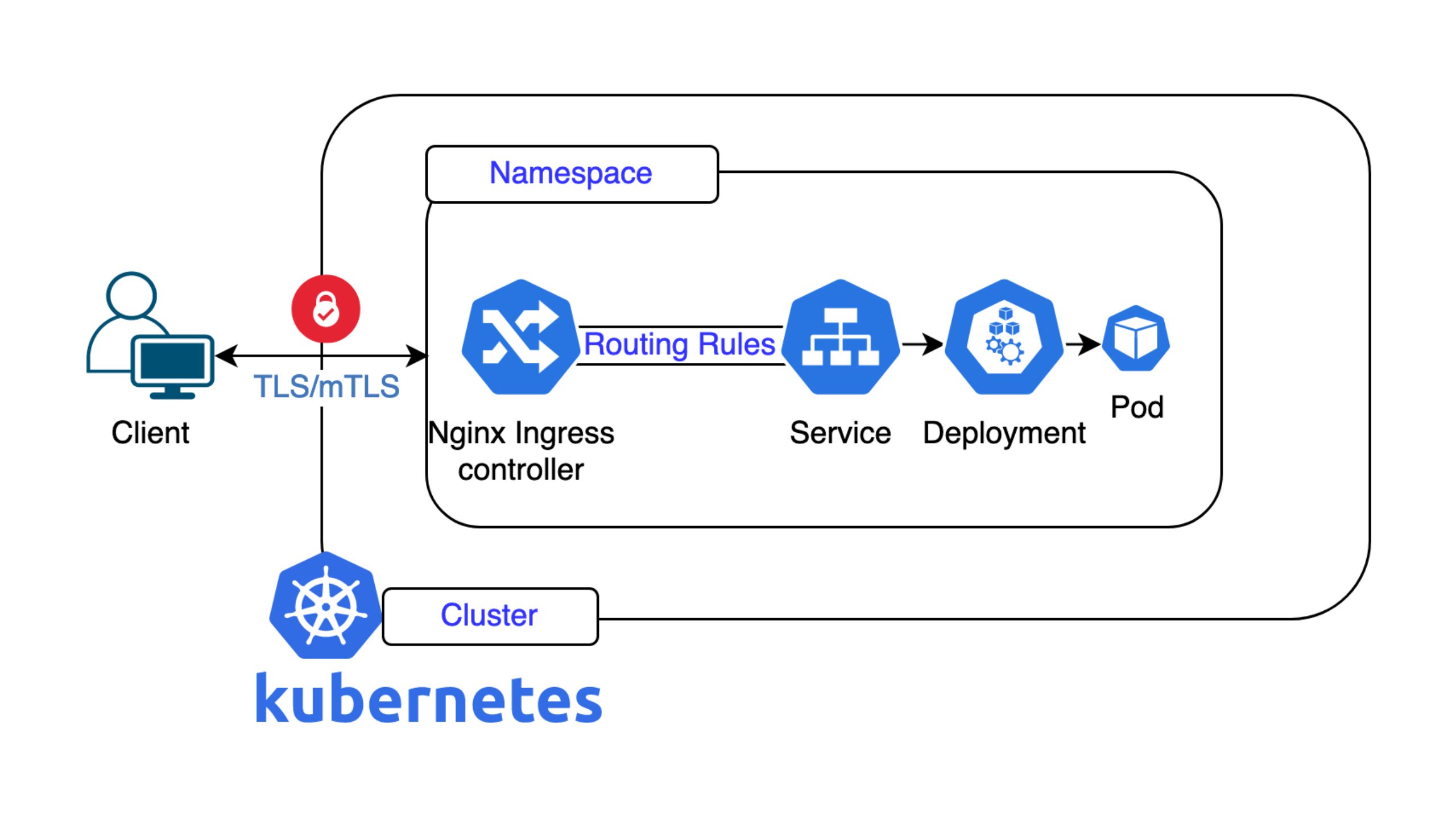
In this talk, Patrick presented a deep technical walkthrough of the Nutanix Kubernetes Platform (NKP), explaining how it simplifies the deployment, operation, and management of Kubernetes environments. Drawing on years of firsthand experience running containerized workloads, he highlighted the challenges of Kubernetes complexity and how NKP is designed to solve them through an integrated, supported platform.
Patrick began by acknowledging Kubernetes’ power: it enables containerization, scalability, faster deployments, and efficient DevOps workflows. However, running Kubernetes in production is far from simple. A complete platform requires numerous components – monitoring (Prometheus, Grafana), logging (Loki), CI/CD integration, cost management, and more. While all of these tools exist in the open-source ecosystem, maintaining compatibility among them is difficult. For example, a Prometheus update can unexpectedly break compatibility with kube-apiserver or kubectl versions. This complexity is where NKP steps in.
NKP provides a fully validated, integrated Kubernetes stack, backed by Nutanix support. Instead of requiring multiple specialized engineers to maintain diverse components, NKP bundles them into one platform with guaranteed compatibility and lifecycle management. Patrick emphasized that this reduces operational pain significantly, allowing teams to focus on workloads rather than platform maintenance. He also explained how NKP separates responsibilities among infrastructure administrators, platform engineers, and developers using role-based access control. This avoids situations like late-night calls for urgent deployments – developers can push code via GitOps processes, which NKP integrates cleanly through APIs.
A central design consideration in Kubernetes is whether to use self-managed clusters or separate management clusters. Patrick compared architectures where control planes run independently or together. NKP supports multi-site high availability: for example, one site can go down without affecting workloads in another site because workload clusters continue operating even if the management plane temporarily becomes unavailable. NKP uses standard Kubernetes interfaces and APIs, allowing organizations to switch platforms later if desired. It also simplifies common administrative actions through Cluster API integration, offering tools that abstract away complex kubectl operations.
A major advantage is automated cluster lifecycle management. NKP manages bootstrap cluster creation, API component installation, and cleanup – tasks that otherwise require extensive manual work. This includes three installation options: a user-friendly UI, a more advanced CLI for fine-grained configuration (e.g., selecting ingress controllers), and fully manual declarative config files for advanced users.
Patrick then discussed private container registries, strongly recommending them over public registries for enterprise Kubernetes clusters. Public images pose security risks, may be altered or removed, and cannot be used in air-gapped environments. Tools like Harbor allow organizations to store vetted images and run internal security scans. For observability, NKP includes Grafana, Prometheus, and Loki by default, offering built-in metrics, logs, and dashboards without requiring separate setup.
Patrick highlighted the importance of correctly setting resource requests and limits to avoid instability – too-strict limits can put applications like Tomcat into crash loops, while too-loose settings waste resources. He concluded by emphasizing that successful Kubernetes operation requires sizing nodes appropriately (fewer large nodes vs. many small nodes), careful workload planning, and complete visibility into cluster health – all areas where NKP provides integrated support.
RAM xor Downtime
In the second talk, Josua focused on the experience of an application developer with small-scale applications migrating from the Heroku platform to a Kubernetes-based solution like Deploio. He emphasized that his apps are «really not Facebook» and that the complexity introduced by modern container orchestration systems often outweighs the benefits for smaller users.
Josua’s applications are generally small, such as one handling all KPIs for 50% of the temporary staffing market, aggregating data from only 10 API users and two GUI users, where political decisions are made based on the data. Another example has 10,000 requests per minute, which is still «very much not Facebook».
Josua advocated for the Heroku development ideal, especially as it existed around 2007, where the developer could focus almost entirely on the code and product. Heroku was built on the idea of simplicity: an app is just an app, and things like the database, networking, load balancing, and logging are a sideshow handled by sensible defaults. The original ideal even featured an in-browser code editor and one-button deployment, although this evolved later. The concept of being able to «just press save to deploy» is a core tenet.
Renuo, desiring a Swiss alternative, teamed up with us to develop Deploio, which functions as the «Swiss Heroku». Renuo has since migrated almost all their 150 Heroku apps to Deploio, which has run in production for a year without a major outage.
Despite Deploio’s reliability, Josua expressed significant frustration that Kubernetes concepts are «leaking» into the simple developer experience. He believes the promised magic of Kubernetes, the «silver bullet for all your problems», has not yet been fulfilled for users who are not on a massive scale like Facebook.
His main complaints about the complexity included:
- Complex terminology: Kubernetes has overly complex terminology, contrasting with the simple model of a process listening on a port (like CGI).
- Inability to rename apps: Currently, apps on Deploio cannot be renamed without tearing them down or copying them, which Josua suspected is due to difficulties in consistently keeping labels on Kubernetes configurations.
- Persistent storage limitations: Josua noted that the 12-factor app model he is used to (where files are not used and object storage like S3 is preferred) makes persistent file support difficult to get without significant cost in the Kubernetes environment. He also noted a movement in Rails toward using SQLite with fast SSDs, highlighting that file support is more relevant for smaller apps that don’t write heavily.
- RAM vs. downtime for single replicas: The central issue, which gave the presentation its title, is the forced trade-off for small apps. For apps running only a single replica, downtime is guaranteed when a node is being depleted, as a new node has to be created and the app moved. Running a second replica to prevent this means doubling the RAM cost (e.g., from 30K to 60K per year), which is a huge increase for small users, unlike for massive apps where a replica is just a small percentage increase. The ability to temporarily duplicate a replica during a node move is complicated because the application developer may not expect two instances to be running.
Josua concluded by noting that even Heroku is moving away from what made it great, beginning to experience Kubernetes-like downtime as they shift to their next-generation platform. The core message was that the complexity of large-scale solutions is «leaking» into the small app development world, and he dislikes it. He urged Deploio to become easier, fulfilling the expectations of developers like him.
Data Localization for Application Services at Cloudflare
The last presentation, held by Josip, provided a deep dive into Cloudflare’s approach to data localization, driven by increasing customer concerns around data privacy and compliance with local laws.
Cloudflare operates an Anycast network (referred to as the «connectivity cloud») that ingests traffic closest to the end-user (the edge) for optimal performance and immediate security services. This architecture enables Cloudflare to mitigate DDoS attacks and inspect traffic globally at the edge without backhauling it to a central location. However, this standard process requires TLS decryption and offloading at the edge. In the default configuration, a copy of the customer’s server-side TLS keys must be present on every Cloudflare POP (Point of Presence) globally to allow for Layer 7 inspection and security filtering. This default behavior is precisely what raises data localization and privacy concerns for enterprise customers seeking technical measures to enforce data sovereignty.
To address these issues, Cloudflare offers the Data Localization Suite (DLS), which provides technical control over the three core aspects of data locality: where the keys are stored, where the decryption happens, and where the connection metadata is stored.
- Regional services: This component allows customers to designate a specific geographic region (e.g. Europe, Switzerland) where Layer 7 inspection and decryption can occur. If a user connects to a POP outside the configured region, that POP will only apply Layer 3 DDoS mitigation techniques and forward the traffic uninspected until it reaches the allowed region for full decryption, which is officially supported for Switzerland.
- GeoKey manager: It allows customers to control the region where their uploaded custom TLS certificates (keys) are stored and where the initial encryption/decryption happens.
- Customer metadata boundary: A feature that gives customers control over the storage location of traffic logs and metadata, with the current options being the European Union or the United States.
Josip continued by saying that for customers who want to ensure their private key material never leaves their own security boundary, Cloudflare offers Keyless SSL as a fallback or primary solution.
In this setup, the customer hosts their private keys on their own key server, which can be hooked up to an HSM (Hardware Security Module) using the open-source GoKeyless binary. Cloudflare never holds the private key; instead, the key server signs session tickets. Cloudflare can then still perform Layer 7 protection (like WAF and DDoS mitigation) using session keys derived from this process, ensuring the customer retains full custody of their master private key.
Josip concluded by emphasizing Cloudflare’s core commitment to privacy, including its investment in privacy-protecting protocols and its policy of not monetizing customer data, reinforcing the technical and contractual frameworks for data compliance.
Want to Stay Up to Date?
Subscribe to our YouTube channel and regularly visit our website’s blog.