











Vielleicht haben Sie bereits bemerkt, dass wir unser S3-Produkt überarbeitet haben und nun eine Migration zur Version 2 des Produktes möglich ist. In diesem Blogbeitrag möchten wir die Gründe für diese Entscheidung erläutern. Dabei möchten wir beleuchten, wie wir die technischen Herausforderungen angegangen sind, und ein Fazit ziehen. Hat sich der Aufwand gelohnt? Also los, Kaffee (oder Tee) schnappen, sich zurücklehnen und mit uns in die Details der Produktüberarbeitung eintauchen.
Warum
Bereits seit Einführung des v1 S3 Produkts auf der Self-Service-Plattform von Nine Mitte 2021 traten immer wieder Probleme auf. Die Produktnutzung war also nicht gerade reibungslos.
Die erste Version unseres S3-Service stellt eine Abstraktion eines von einem Drittanbieter bezogenen Managed Services dar. Dieses Servicepaket umfasst neben der Software auch den Support und die dedizierte Hardwareumgebung, die durch den Anbieter betrieben wird.
Bereits kurz nach der Einführung des S3-Produktes haben uns Kundenanfragen erreicht, bei denen uns klar wurde, dass die Umgebung entgegen ersten Tests nicht die Breite aller Kundenanforderungen erfüllt. In unserer Testumgebung konnten wir diese Erfahrungen reproduzieren. Teilweise niedriger Datendurchsatz und Verbindungsabbrüche verzögerten unsere Entwicklung teils erheblich. Leider waren unsere Beobachtungen nicht nur auf die Testumgebung beschränkt.
Die relevanten Leistungsmerkmale waren auch in der Produktionsumgebung ungenügend. Trotz des geschlossenen Servicevertrages konnte uns der Support des Anbieters keine praktikablen Lösungsansätze aufzeigen. Da einige unserer Produkte und Entwicklungsabläufe auf dem S3-Produkt aufbauen, konnten wir die Frustration unserer Kund*innen bestens nachvollziehen. Der Bedarf für eine Verbesserung des S3-Produktes war offensichtlich.
Aufgrund der technischen Einschränkungen des Produktes und des mangelnden Supports des Herstellers wurde uns früh bewusst, dass unser Ziel, eines auf Self-Service ausgerichteten, skalierbaren und leistungsfähigen S3-Produktes nur durch eine Neuentwicklung erreichbar ist.
Was
Unsere Evaluationskriterien umfassten neben der Leistungsfähigkeit insbesondere auch die Integrationsmöglichkeiten in unsere Self-Service API. Nach der Evaluation mehrerer Produkte haben wir uns für Nutanix Objects als künftige Lösung entschieden.
Da wir die Lösungen und Infrastruktur von Nutanix bereits in all unseren Rechenzentrumsstandorten für die Bereitstellung anderer Produkte nutzen, beispielsweise virtuelle Server und unser Produkt NKE, konnten wir auf den bestehenden Plattformen aufbauen und bereits existierende Automationsansätze über die Nutanix API für das neue Produkt ausbauen.
Wie
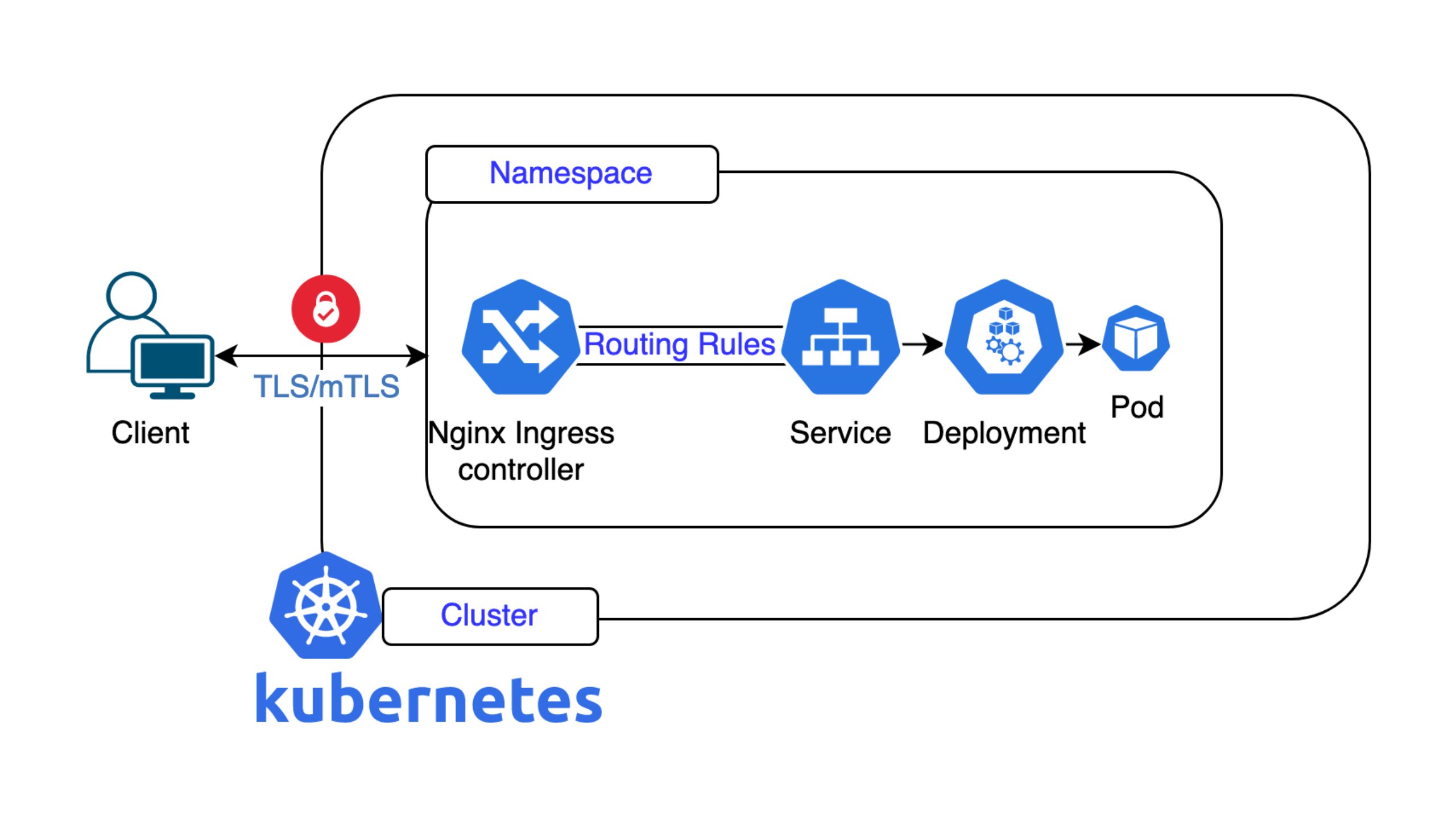
Ein bestehendes Produkt zu ersetzen, bringt besondere Anforderungen an das «Wie» der Implementation mit sich. Nicht nur möchten wir unseren Kund*innen so schnell wie möglich ein besseres Produkt anbieten können, auch die Datenmigration soll so einfach wie möglich vonstattengehen. Von Beginn an lag unser Fokus darauf, unseren Kund*innen eine automatisierte Datenmigration anzubieten, welche die Daten Ende zu Ende verschlüsselt innerhalb der Nine Infrastruktur migriert – ganz ohne unsere Kundschaft mit Down- oder Uploads von Daten zu beschäftigen.
Neben der Automation der Datenmigration war die Integration der Lösung in unsere Self-Service-API für uns sehr wichtig. Auch hier sollte für unsere Kund*innen keine nennenswerte Änderung bei der Nutzung der API entstehen. Daher haben wir Unterschiede im Backend der API abstrahiert, sodass Kund*innen lediglich den Parameter «backendVersion» auf den Wert «v2» setzen müssen, um neue Buckets auf Basis des neuen Produktes zu erstellen. Zwischenzeitlich wurde dies als neuer Standard festgelegt.
Um ein v1-Bucket zu migrieren, müssen die folgenden Informationen bereitgestellt werden:
- Ein v1-Quell-Bucket sowie ein Benutzer mit Leseberechtigung
- Ein v2-Ziel-Bucket sowie ein Benutzer mit Schreibberechtigung
- Festlegung eines Intervalls für den Abgleich der Buckets
- Ein Parameter, der angibt, ob Daten, die im Ziel-Bucket vorhanden sind, überschrieben werden sollen
Für die Datenmigration nutzen wir rclone, ein äusserst empfehlenswertes Tool für die Verwaltung von S3-Buckets. Für die Migration nutzen wir zwei rclone Funktionen: sync und copy.
Mit sync werden Ziel- und Quell-Bucket synchronisiert. Dabei werden auch alle Daten im Ziel-Bucket entfernt, die nicht (mehr) im Quell-Bucket vorhanden sind.
rclone sync source:sourcepath dest:destpath
Mit copy werden die Daten hingegen vom Quell-Bucket in das Ziel-Bucket kopiert, ohne Daten im Ziel-Bucket zu löschen.
rclone copy source:sourcepath dest:destpath
Die rclone-Befehle werden in Kubernetes-Pods innerhalb unserer Infrastruktur ausgeführt. So stellen wir neben der Ende-zu-Ende-Verschlüsselung sicher, dass die Daten auch während der Migration unser Netzwerk nicht verlassen.
apiVersion: batch/v1
kind: CronJob
metadata:
name: bucketmigration
namespace: myns
spec:
jobTemplate:
spec:
parallelism: 1 schedule: 7,22,37,52 * * * *
spec:
containers:
- args:
- copy
- source:<bucketname>
- dest:<bucketname>
command:
- rclone
image: docker.io/rclone/rclone:1.65.2
name: rclone
Die abgebildete CronJob-Definition startet schlussendlich einen rclone KubernetesPod, der den Migrationsprozess ausführt.
Im nächsten Schritt schauen wir uns an, wie eine Migration einer Applikation auf das neue S3-Produkt ablaufen kann. Exemplarisch migrieren wir eine Applikation, die wir selbst betreiben: Loki, einen Dienst zur Aggregation von Logfiles.
Vorbereitend wurde ein v2-Bucket erstellt. Für die Migration wurde ein copy-Job erstellt. Das Ziel-Bucket enthält keine Daten, ein sync-Job war daher nicht notwendig. Da auch später lediglich ein Delta des Quell-Buckets übertragen werden soll, könnte ein sync-Job gar zu einem Datenverlust führen, da wir im weiteren Verlauf die Applikation auf das Ziel-Bucket schreiben lassen.
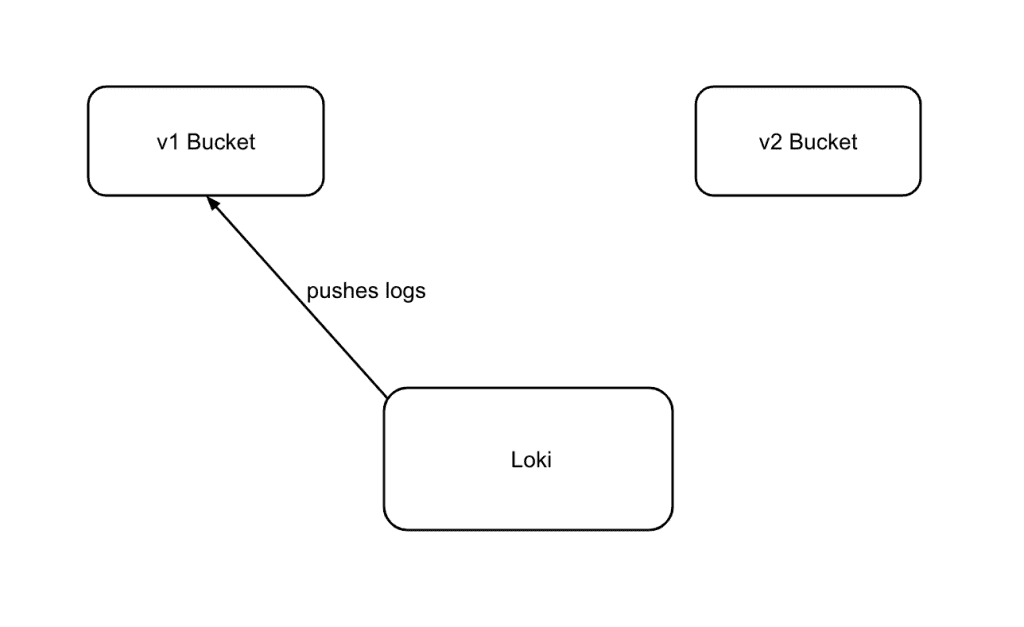
Im ersten Schritt erstellen wir einen Bucket-Migrations-Job über die Nine-API.
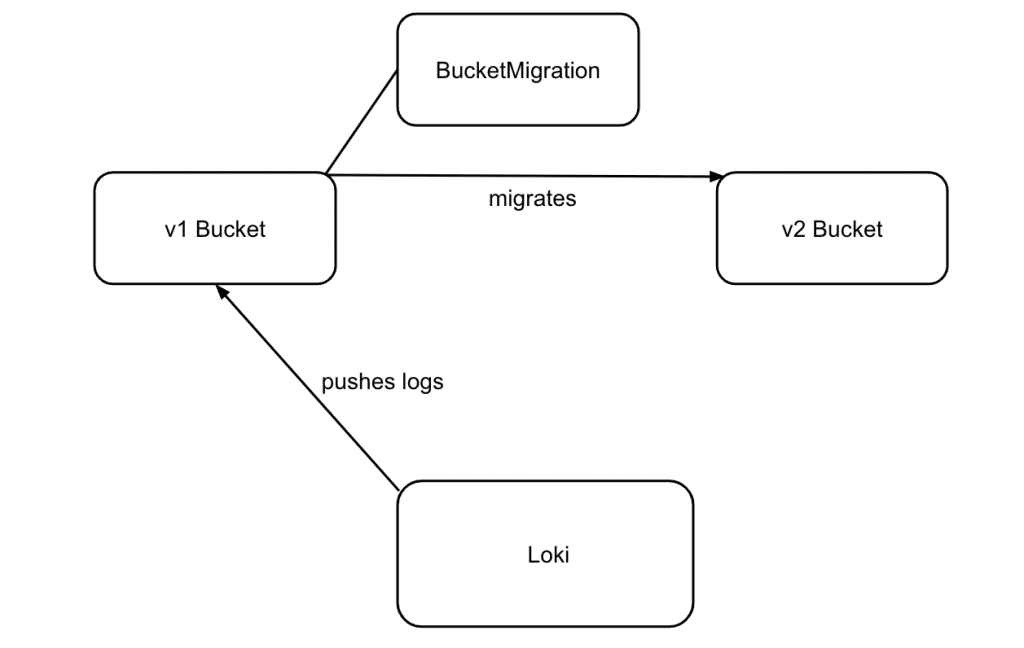
Nach dem ersten Durchlauf des Migrations-Jobs können wir Loki so konfigurieren, dass die Logs fortan in das v2-Bucket geschrieben werden.
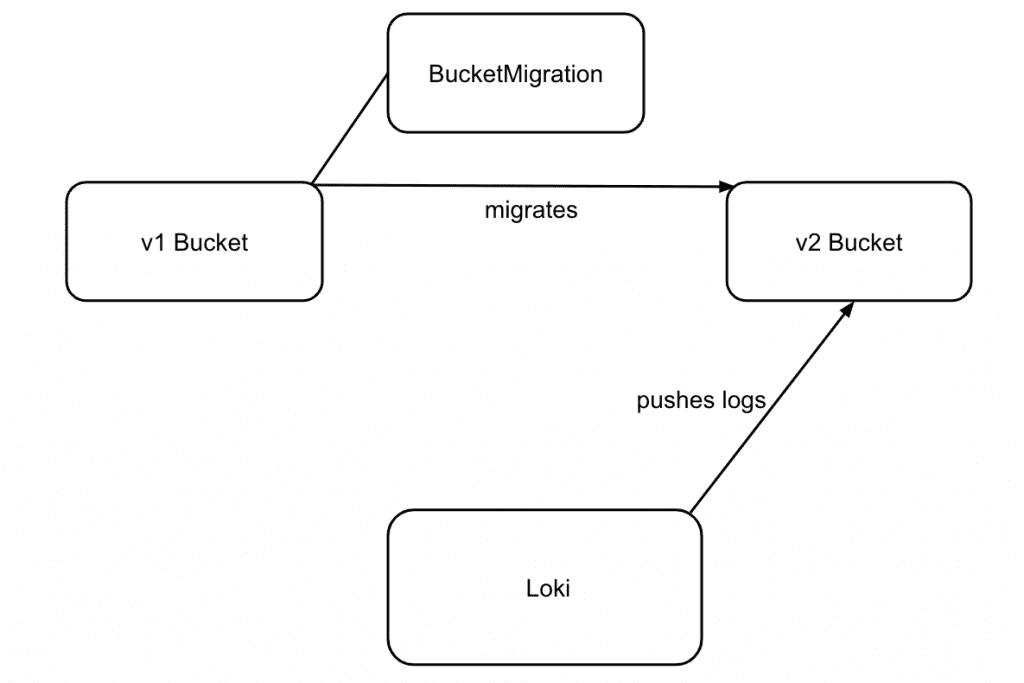
Nachdem die Loki-Konfiguration angepasst wurde, lassen wir einen weiteren Migrations-Job ausführen. So übertragen wir die Daten aus dem v1-Bucket, die zwischen der ersten Ausführung des Jobs und der Anpassung der Applikation auf das v2-Bucket geschrieben wurden.
Würden wir statt eines copy-Jobs einen sync-Job verwenden, würde das Delta im v2-Bucket gelöscht werden. Mit dem erneuten Abgleich der Buckets ist die Datenmigration und die Umstellung der Applikation abgeschlossen.
Fazit
Ein Produkt abzulösen, stellt immer eine besondere Herausforderung dar. Leistung, Automatisierungsgrad, Simplizität in der Benutzung, der Migrationspfad und der Preis spielen in der finalen Betrachtung eine grosse Rolle.
Unsere Kundschaft hat uns vielfach berichtet, dass die Leistung des v2 S3-Produktes merklich besser ist als die seines Vorgängers. In unseren automatisierten Code- und End-to-End Tests konnten wir dies ebenfalls beobachten. Wo wir vormals häufig mit Abbrüchen der Tests konfrontiert waren, ist das S3-Backend nun kein limitierender Faktor mehr. Leistungstests haben gezeigt, dass das Hochladen einzelner Objekte teils weniger als die Hälfte der Zeit benötigt, als dies bei der vorherigen Lösung der Fall war. Unser konsequenter Fokus auf Automatisierung, auch für die Datenmigration, baut den Automatisierungsgrad weiter aus.
Neben gesteigerter Leistung und ausgebauter Automation konnten wir auch den Preis für unsere Kund*innen drastisch senken. Das konsequente Aufbauen auf bestehenden Lösungen hat es uns ermöglicht, den Preis um 66% von 0,09 CHF auf 0,03 CHF pro Monat und Gigabyte zu senken.
Wir sind glücklich, dass wir heute nicht nur ein schnelleres und verlässlicheres Produkt, sondern auch ein kostengünstigeres offerieren können.
Die Ablösung des bisherigen Produktes kann guten Gewissens als Win-Win-Situation bezeichnet werden, und wir könnten mit dem Ergebnis zufriedener kaum sein.
Ein Ausblick in die Zukunft
Derzeit ist die Funktion der Bucket Migration darauf beschränkt, Daten zwischen v1- und v2-Buckets zu synchronisieren. In naher Zukunft planen wir, diese Funktionalität zu erweitern und auch die Synchronisierung zwischen v2-Buckets zu unterstützen.
Darüber hinaus prüfen wir die Möglichkeit, die Migration extern betriebener Buckets zu ermöglichen. So wäre es beispielsweise denkbar, unser S3-Produkt zum Zweck eines Offsite-Backups zu nutzen; oder auf einfache Art und Weise Daten in unsere Umgebung zu migrieren. 🙂
Wir hoffen, unser Blog konnte Ihre Kaffee- oder Tee-Pause versüssen und freuen uns auf Ihre Rückmeldung. Sollten Sie eine Bucket-Migration planen und sich über Detailfragen unschlüssig sein, zögern Sie nicht, mit uns in Kontakt zu treten.