
















Unser TechTalkThursday #20 fand am 02. Mai 2024 um 18.00 Uhr statt. Wir durften dabei zwei externe Referenten willkommen heissen und auch ein 9er gab eine Präsentation. Etwa 30 Zuhörer*innen waren bei dem Event präsent. Darunter waren viele Mitarbeiter*innen von Nine, aber auch einige Gäste der Lektoren und externe Teilnehmer*innen mit Interesse an den Themen zentralisierte Suchmaschinen, Retrieval-Augmented Generation und KI.
Dabei feierten wir nicht nur ein kleines Jubiläum – die 20. Edition unserer TechTalkThursday-Reihe – wir durften auch stolz unser eigenes Bier vorstellen: «Deploibroi». Dieses Bier haben wir zusammen mit unserem deplo.io-Partner Renuo AG und der Braugenossenschaft Gsöff in Zürich entwickelt. Das Bier (sowie die Gratis-Snacks) kamen sehr gut beim gesamten Publikum an.
Thomas Hug, Gründer und CEO von Nine, leitete den Event ein, indem er kurz die Sprecher und deren Themen vorstellte. Die drei Experten des Abends waren: Kevin Ferranti, Software Engineer bei Nine, Griffin White, Gründer von GWCustom, und Vito Cudemo, Gründer von und Software Engineer bei Solity.
Scouter: eine zentralisierte Suchmaschine
Kevin erläuterte die Entwicklung und Funktionalität von Scouter, einer zentralisierten Suchmaschine für Ticketsysteme. Das Projekt war auch Thema seiner Bachelorarbeit.
Warum Scouter?
Scouter geht auf zwei Hauptthemen ein: die Archivierung und Suchfunktionalität in IT-Supportsystemen. Dabei soll der Datenzugriff vereinfacht und die Effizienz erhöht werden, mit der IT-Supportprobleme gelöst werden, indem vorhandene Tickets und ältere Interaktionen genutzt werden.
Kevin erklärte dazu, dass ihn vor allem die aktuelle Praxis, mehrere Ticketsysteme laufen zu lassen, nur um auf die Daten zugreifen zu können, zur Entwicklung von Scouter angeregt hat. Diese Methode ist ineffizient und kostspielig. Da die Daten in Scouter zentralisiert sind, wird die Integrität und Unveränderlichkeit archivierter Daten verbessert. Dadurch wird wiederum ein nicht autorisierter Zugriff verhindert und der zeitliche Kontext bleibt erhalten.
Archivierung
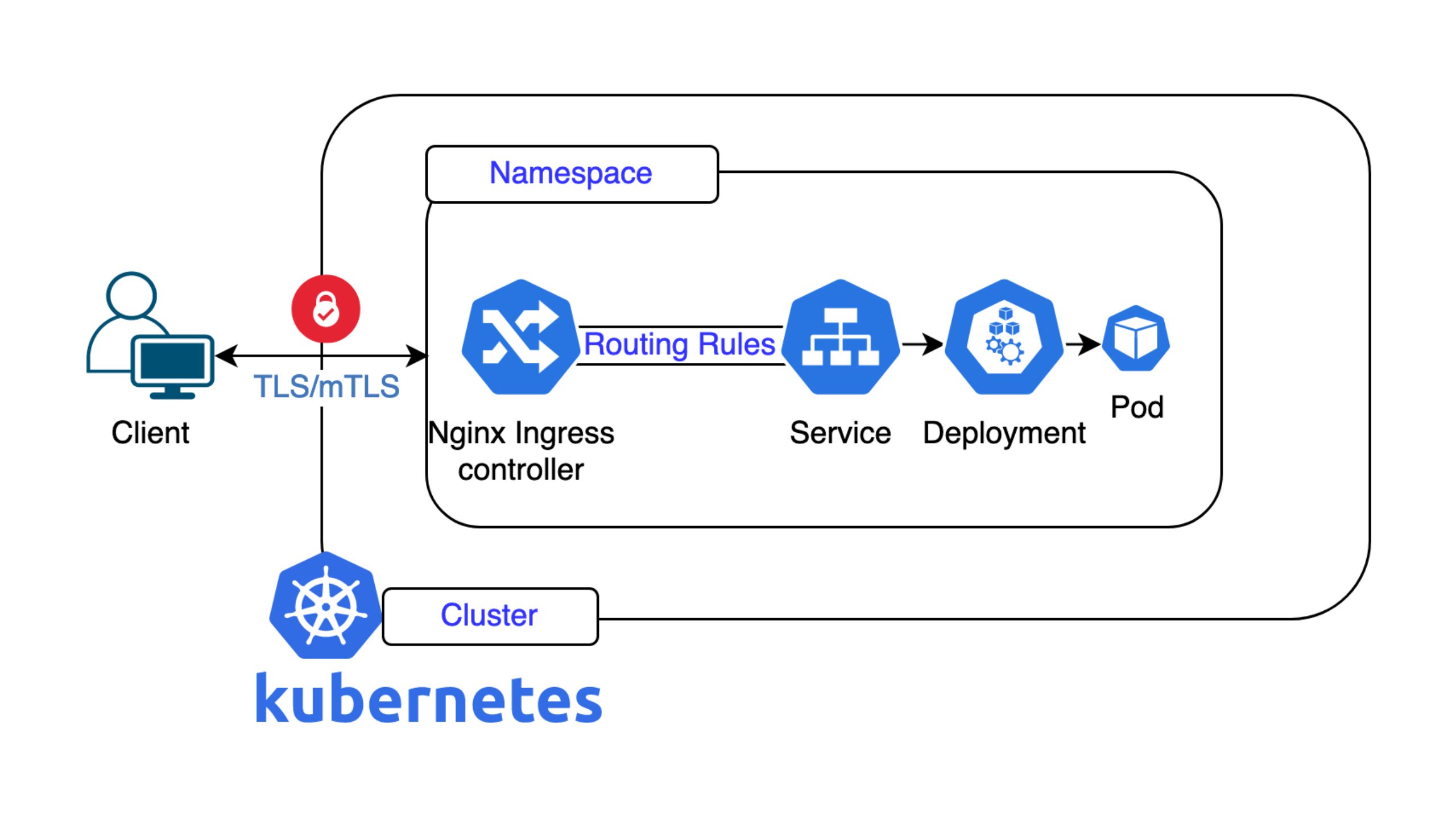
Beim Archivierungsprozess innerhalb von Scouter werden Datenbankabzüge von Ticketsystemen wie etwa OTRS und Jira erstellt. Diese Kopien werden auf einem neuen Datenbank-Management-System (DBMS) auf einem Zielserver gespeichert. Die dort vorhandenen Daten können nur gelesen werden, damit keine Veränderungen an ihnen durchgeführt werden können. Mit dieser Methode wird der semantische Kontext und die Metadaten erhalten, sodass die Daten sinnvoll und verständlich bleiben.
Vorteile der Datenbankabzüge
- Semantischer Kontext: Tabellenstrukturen und Beziehungen werden erhalten, sodass die Daten ihren Sinn und ihre Nutzbarkeit beibehalten.
- Einfaches Format: Es werden SQL-Statements verwendet, die User*innen leicht lesen und verwalten können.
- Unabhängigkeit: SQL-Statements sind nicht vom Speichermedium abhängig und benötigen nur ein kompatibles DBMS wie MySQL oder Postgres.
- Umfassendes Backup: Alle notwendigen Daten werden archiviert und können jederzeit wiederhergestellt werden.
Suchmaschinenfunktionalität
Die Suchmaschine von Scouter ist für unternehmerische Zwecke gedacht und bietet Features, die für einen effektiven IT-Support von grosser Bedeutung sind. Dazu gehören:
- Ranking nach Relevanz: Suchergebnisse werden nach Relevanz aufgelistet, wobei aktuellere Tickets eine höhere Priorität erhalten.
- User-Notizen: User*innen können Tickets mit Notizen und Bewertungen versehen, sodass die Suchmaschine mit der Zeit zunehmend nützliche Resultate bieten kann.
- Treffer-Hervorhebung: In den Suchergebnissen vorkommende Schlüsselbegriffe werden hervorgehoben, sodass relevante Informationen einfacher identifiziert werden können.
- Erweiterte Suchfilter: Bedingungsoperatoren, Platzhaltersuche, unscharfe Suche und andere erweiterte Suchfunktionalitäten werden durch die Integration von Apache Solr unterstützt.
Genutzte Technologien
Die Anwendung wurde mit Ruby on Rails entwickelt und setzt auf verschiedene Integrationen, um ihre Ziele umzusetzen:
- Apache Solr: für Suchfunktionalitäten
- GitLab: um Kontextinformationen über REST API abzurufen
- Postgres: als DBMS zum Speichern von Notizen und Bewertungen
Vor- und Nachteile
Kevin schätzt die Vor- und Nachteile von Scouter wie folgt ein:
- Vorteile:
- Zentralisierter Zugriff auf alte Tickets
- Bessere Datenintegrität und -speicherung
- Verbesserte Suchfunktionalitäten, die auf die Bedürfnisse des IT-Supports zugeschnitten sind
- Nachteile:
- Einige Features, wie etwa die Facettensuche und Replizierung, sind noch nicht vollständig umgesetzt
- Mögliche Herausforderungen bei der Technologie-Austauschbarkeit und bei der Skalierbarkeit
Zukünftige Schritte
Für Scouter werden die nächsten Schritte Folgendes bringen:
- Implementierung weiterer Features, wie etwa die Facettensuche
- Finden von Lösungen zur Replizierung, um die Datenredundanz zu verbessern
- Fortlaufende Einschätzung und Verbesserung basierend auf User-Feedback und technischem Fortschritt
Retrieval-Augmented Generation: die nächste Generation der Informationssuche
Griffin konzentrierte sich in seiner Präsentation auf die Fortschritte und Anwendungen KI-basierter, durchsuchbarer Systeme. Er sprach dabei über die Entwicklung und das Deployment einer hochbandbreiten Schnittstelle für die Indexierung von Wissen, welche auf die Bedürfnisse von IT-Spezialist*innen zugeschnitten ist. Die Systeme sollen eine Reihe an Webseiten gleichzeitig indexieren können, sodass Wissensmanagement und Wissensabruf effizienter werden.
Highlights
Als wichtiges Feature wurde hervorgehoben, dass das System massgeschneiderte Lösungen unterstützt, sodass es auf die Bedürfnisse unterschiedlicher Organisationen eingehen kann. Dabei sind auch lokale Deployments möglich und die Skalierbarkeit ermöglicht die Indexierung grosser Datenvolumen. Mithilfe eines API-Keys können Nutzer*innen tausende von Dokumenten indexieren. Damit bietet Retrieval-Augmented Generation eine robuste und flexible Schnittstelle für das Informationsmanagement grosser Datenvolumen.
In seiner Präsentation verwies Griffin auch auf den ständigen Wandel des Wissensstands und die Notwendigkeit von Systemen, die sich diesen Veränderungen anpassen können. Er erläuterte, dass Wissen kontinuierlich aktualisiert wird, sodass ein Backend notwendig ist, das diese Aktualisierungen widerspiegelt. Das Ziel dabei ist es, ein zentrales, leicht durchsuchbares Repository aufzubauen, sodass IT-Expert*innen weniger Zeit damit verbringen, Informationen an verschiedenen Orten zu suchen. Diese Zentralisierung von Informationen soll Workflows vereinfachen und die Effizienz steigern.
Die Entwicklung von Suchmaschinen
Griffin ging auch auf die Geschichte von Suchsystemen ein, wobei er klassische Organisationssysteme wie etwa die Kartenkataloge in Bibliotheken modernen KI-basierten Suchmaschinen gegenüberstellte. Dieser Vergleich verdeutlicht noch einmal die Fortschritte im Bereich Suchtechnologie und die erhöhte Effizienz und besseren Zugangsmöglichkeiten der aktuellen Systeme.
Dann folgte eine Demonstration der Fähigkeiten des Systems, wobei seine nutzerfreundliche Oberfläche und leistungsstarken Suchfunktionalitäten hervorgehoben wurden. Nutzer*innen können dabei Gespräche, Notizen und Links zu Tickets nutzen, um auf das gespeicherte Wissen zuzugreifen. Das System wurde so entwickelt, dass der jeweils relevante Kontext – z. B. eine Veränderung in Code Repositories wie GitLab – farblich markiert wird, um Nutzern jederzeit Zugang zu umfassenden Informationen zu ermöglichen.
Technische Spezifikationen
Weiterhin ging es in der Präsentation auch um die technischen Aspekte des Systems, wobei die Hauptanwendung auf Ruby on Rails basiert und Apache Solr für die Indexierung genutzt wird. Das System unterstützt auch Datenbank-Management-Systeme, wie sie von beliebten Ticket-Plattformen wie Jira oder OTRS verwendet werden. Griffin erklärte, dass die effiziente Archivierung von Daten eine wichtige Rolle im Entwicklungsprozess spielte, wobei Datenbankabzüge für ihn die beste Lösung für die Archivierung darstellen.
Insgesamt bot Griffin einen erkenntnisreichen Überblick über ein fortgeschrittenes, KI-basiertes Suchsystem, das IT-Expert*innen die Verwaltung und Abfrage von Informationen erleichtert. Da das System grosse Datenvolumen indexieren, Aktualisierungen wiedergeben und ein zentrales, durchsuchbares Repository bieten kann, stellt es einen bedeutenden Schritt im Bereich Informationsmanagement dar.
KI & LLM im geschäftlichen Einsatz und eine kurze Demo mit docs.nine.ch
Leider war Vitos Präsentation nicht zu seiner vollen Zufriedenheit und enthielt darüber hinaus Informationen, die er nur mit dem Publikum vor Ort teilen wollte. Daher können wir keine Aufzeichnung oder Zusammenfassung seines Lektorats bereitstellen. Er hat allerdings versprochen, dass er so bald wie möglich mit einer professionellen Präsentation und einem Produkt zurückkehren wird, das sich – in seinen Worten – besser für die Öffentlichkeit eignet.
Sie wollen auf dem Laufenden bleiben?
Abonnieren Sie unseren YouTube-Kanal und schauen Sie regelmässig in unseren Blog.