















Nachdem wir hier im Blog bereits unser neues Monitoringsystem Prometheus vorgestellt haben, welches unsere Nagios Installation ersetzt hat, möchte ich in diesem Beitrag etwas tiefer in die technischen Details der Implementierung eintauchen. Dazu möchte ich zunächst die unterschiedlichen Quellen für Prometheus-Metriken vorstellen und speziell auf den “Node Textfile Collector” als flexible Lösung für die Erstellung einfacher Metriken eingehen.
Anhand eines Praxis-Beispiels zeige ich anschliessend noch, wie sich ein vorhandenes Nagios-NRPE-Script so umbauen lässt, dass es zur Generierung von Prometheus-Metriken weiterverwendet werden kann.
Prometheus Quellen
Unsere Prometheus Monitoring Server beziehen Ihre Metriken direkt von den zu überwachenden Systemen. Diese werden dem Monitoringserver über eine HTTP-Schnittstelle zur Verfügung gestellt. Um Prometheus-kompatible Metriken von einer Anwendung zu erhalten, gibt es mehrere Möglichkeiten:
Im einfachsten Fall stellt eine Applikation wie zum Beispiel RabbitMQ (ab Version 3.8.0) oder Traefik Prometheus-kompatible Metriken selbst zur Verfügung.
Generiert die zu überwachende Applikation keine eigenen Metriken, können diese über einen separaten Prometheus Exporter erstellt werden. Der Exporter kommuniziert mit der jeweiligen Applikation und erstellt aus deren Performance-Werten Prometheus-kompatible Metriken, die der Monitoringserver per HTTP-Request auf dem jeweiligen Exporter-Port abfragen kann. Fertige Prometheus Exporter stehen für eine grosse Zahl von Applikationen zur Verfügung.
Gibt es keinen fertigen Exporter für den gewünschten Einsatzzweck, besteht noch die Möglichkeit, einen eigenen Exporter zu schreiben. Gerade bei einfach zu generierenden Metriken stellt die Implementierung aber einen relativ grossen Aufwand dar. Falls die Metrik auch nicht in Echtzeit aktualisiert werden muss, ist daher ein Textfile Collector für den Node Exporter eine sinnvolle Alternative.
Textfile Collector Scripts für den Node Exporter
Der Prometheus Node Exporter stellt grundlegende Hardware- und Betriebssystem-Metriken zur Verfügung. Er ist daher auf jedem unserer Managed Server installiert. Zusätzlich zu den vorhandenen Metriken bietet er die Möglichkeit, über den integrierten Textfile Collector selbst erstellte Metriken aus Textfiles im Prometheus-Format bei Abfragen mitzuliefern. Wie diese Textfiles erstellt werden, ist unerheblich, so dass hierfür jede Form von Scripts genutzt werden kann. Dieses muss nur per Cronjob regelmässig ausgeführt werden, um die Metriken zu aktualisieren. Dafür kann beispielsweise ein Shellscript verwendet werden. Wichtig ist lediglich, dass das Script die generierten Metriken im passenden Format ausgibt.
Bei der Ablösung unseres Nagios-Monitorings war es ein wichtiges Ziel, alle vorhandenen individuell entwickelten Nagios-Checks auch weiterhin in Prometheus zur Verfügung zu haben. Das sind vor allem Checks, die nur auf einzelnen Maschinen oder interner Infrastruktur zum Einsatz kommen. Gerade hier konnten wir mittels solcher Scripte für den Textfile Collector die vorhandenen Checks auf einfache Art und Weise für unser neues Monitoring verfügbar machen.
Aber auch neue Checks, die bisher nicht in unserem Nagios-Monitoring enthalten waren, lassen sich so schnell und einfach realisieren.
Ein einfaches Textfile Collector Script
Im Folgenden ein einfaches Beispiel für eine Custom Metrik per Textfile Collector Script:
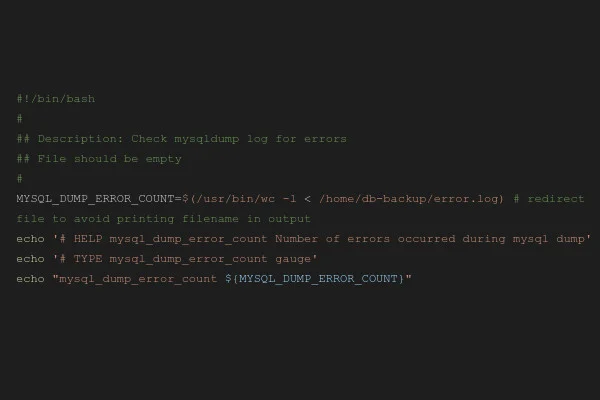
#!/bin/bash
#
## Description: Check mysqldump log for errors
## File should be empty
#
MYSQL_DUMP_ERROR_COUNT=$(/usr/bin/wc -l < /home/db-backup/error.log) # redirect file to avoid printing filename in output
echo '# HELP mysql_dump_error_count Number of errors occurred during mysql dump'
echo '# TYPE mysql_dump_error_count gauge'
echo "mysql_dump_error_count ${MYSQL_DUMP_ERROR_COUNT}"
Bevor das eigentliche nächtliche Backup stattfindet, wird auf unseren Managed Servern zunächst ein MySQL-Dump erstellt, um über eine konsistente Sicherung der Datenbanken zu verfügen. Auch ohne grössere Scriptingkenntnisse lässt sich leicht erkennen, was das obige Shellscript tut: Es prüft den Inhalt der Datei /home/db-backup/error.log, in die Fehler während des SQL Dumps geloggt werden und gibt die Anzahl Zeilen der Logdatei als Metrik “mysql_dump_error_count” aus.
Im Idealfall, also bei leerer error.log-Datei, erzeugt das Script beim Aufruf die folgende Ausgabe:
root@host:~# /usr/local/bin/node_exporter_textfile_collector/mysql_backup.sh
# HELP mysql_dump_error_count Number of errors occurred during mysql dump
# TYPE mysql_dump_error_count gauge
mysql_dump_error_count 0
root@host:~#
Neben der eigentlichen Metrik ist als Kommentar noch eine Erläuterung zu dieser sowie der Typ der Metrik (in diesem Fall “gauge”) definiert. Mehr zu den vier unterschiedlichen Typen von Prometheus-Metriken findet sich hier.
Ein Cronjob ruft das Script jeden Morgen auf, nachdem die Backups abgeschlossen wurden, und schreibt die Ausgabe in eine Datei, die vom Node-Exporter ausgelesen und deren Metriken bei einem Request des Monitoringservers mit an diesen zurückgegeben werden. Auf Seiten des Monitoringservers ist dann nur noch eine passende Regel für diese Metrik erforderlich, in der definiert ist, wann ein Alert ausgelöst werden soll:
- alert: MySQLDumpError
expr: mysql_dump_error_count > 0
for: 5m
labels:
severity: warning
annotations:
summary: "There is an error with mysqldumps on "
description: "Detected an error during mysqldump - see /home/db-backup/error.log"
Alerting Rules werden nach einer festen Syntax erstellt und werten jeweils einen bestimmten Ausdruck aus. In unserem Fall wird eine Warnung für jeden Wert der Metrik grösser 0 generiert (mysql_dump_error_count > 0), da dies auf Fehlermeldungen im Logfile hinweist.
Textfile Collector-Nutzung für Fortgeschrittene: Recycling eines Nagios-Scripts fürs SSL-Expiry-Monitoring
Zum Abschluss noch ein schönes Beispiel aus der Praxis zum Thema SSL-Zertifikate:
Auch bisher schon monitoren wir deren Ablaufdatum, um uns rechtzeitig um deren Verlängerung kümmern zu können. In das Monitoring einbezogen werden alle Zertifikate im Pfad /etc/ssl/certs, deren Dateiname mit SSL_ beginnt. Für die Migration des Checks auf Prometheus kamen folgende Optionen in Frage:
- Die Verwendung eines vorhandenen SSL Certificate Exporters, beispielsweise von diesem: Diese Idee wurde verworfen, da hier Zertifikate im Gegensatz zur bisherigen Lösung über eine TLS-Verbindung von aussen gemonitored werden. Dies hätte den Nachteil, dass bestimmte Zertifikate nicht berücksichtigt werden, z.B. wenn diese nur von einer ausschliesslich intern erreichbaren Applikation verwendet werden.
- Das Schreiben eines eigenen Exporters: Auch dies wäre nicht sinnvoll, da der Aufwand im Verhältnis zu den benötigten Metriken (eigentlich nur Tage bis zum Ablauf und Gültigkeit der Chain) zu gross ist. Eine Aktualisierung der Metriken in Echtzeit ist für diesen Anwendungsfall ebenfalls überflüssig.
- Das Erstellen eines Textfile Collector Scripts: In diesem Fall die einfachste Lösung, daher wurde dieser Ansatz gewählt.
Aber es geht noch einfacher: Warum ein von Grund auf neues Script erstellen, wenn diese Aufgabe jetzt bereits von Nagios per NRPE-Script erledigt wird? Wäre es nicht einfacher, das vorhandene Script an die neuen Erfordernisse anzupassen? Schauen wir uns den relevanten Teil des vorhandenen Ruby-Scripts dazu näher an:
#!/usr/bin/env ruby2.5
...
ssl_certificates = options[:glob_path].map { |g| Dir.glob(g) }.flatten.delete_if { |f| f =~ /(\.chain\.crt|\.csr)$/ }
ok_certs = []
warning_certs = []
critical_certs = []
ssl_certificates.each do |cert_path|
raw = File.read cert_path
certificate = OpenSSL::X509::Certificate.new raw
warning_state_at = certificate.not_after - options[:warning]
critical_state_at = certificate.not_after - options[:critical]
if Time.now >= warning_state_at
if Time.now >= critical_state_at
critical_certs << "#{cert_path} expires in #{(certificate.not_after-Time.now).to_i.seconds_to_days} days"
else
warning_certs << "#{cert_path} expires in #{(certificate.not_after-Time.now).to_i.seconds_to_days} days"
end
else
ok_certs << "#{File.basename cert_path} (#{certificate.not_after.strftime('%Y-%m-%d')})"
end
end
case
when critical_certs.any?
print_message(critical_certs, :critical)
exit_code = 2
when warning_certs.any?
print_message(warning_certs, :warning)
exit_code = 1
else
print_message(ok_certs, :ok)
exit_code = 0
end
exit exit_code
Das Script macht grundsätzlich schon einmal das, was wir benötigen: Es prüft das Ablaufdatum des Zertifikats und berechnet daraus, wie viele Tage dieses noch gültig ist.
Zusätzlich enthält das Script eine Logik, die bestimmt, wann sich ein Zertifikat im Status “OK”, “Warning” oder “Critical” befindet. Diese Logik benötigen wir für Prometheus nicht mehr, da die Bewertung, wann eine Warnung oder ein Alarm ausgelöst wird, wie oben gesehen auf dem Monitoring Server anhand einer Regel bestimmt wird.
Das Script selbst soll uns stattdessen nur die Tage bis zum Zertifikatsablauf im passenden Format zurückgeben. Nach einer Überarbeitung sieht der Ausschnitt so aus:
ssl_certificates = options[:glob_path].map { |g| Dir.glob(g) }.flatten.delete_if { |f| f =~ /(\.chain\.crt|\.csr)$/ }
cert_days_left = []
ssl_certificates.each do |cert_path|
raw = File.read cert_path
certificate = OpenSSL::X509::Certificate.new raw
cert_days_left << "ssl_certificate_days_left{certfile=\"#{File.basename cert_path}\", certpath=\"#{cert_path}\"} #{(certificate.not_after-Time.now).to_i.seconds_to_days}"
end
puts "# HELP ssl_certificate_days_left Days until certificate expiry\n# TYPE ssl_certificate_days_left gauge"
puts cert_days_left.join("\n")
exit_code = 0
exit exit_code
Da ein Grossteil der Logik weggefallen ist, ist das Script entsprechend übersichtlicher geworden. Seine Ausgabe sieht folgendermassen aus:
root@host:~ # /usr/local/bin/node_exporter_textfile_collector/x509_expiry.rb
# HELP ssl_certificate_days_left Days until certificate expiry
# TYPE ssl_certificate_days_left gauge
ssl_certificate_days_left{certfile="SSL_wildcard.nine.ch.crt", certpath="/etc/ssl/certs/SSL_wildcard.nine.ch.crt"} 672
root@host:~ #
Fertig! Das Script gibt uns nun für alle Zertifikate die verbleibende Gültigkeitsdauer in Tagen als Metrik zurück. In Wirklichkeit wurden natürlich noch Änderungen am Optionparser und an weiteren Stellen vorgenommen, aber der grösste Teil der Arbeit ist an dieser Stelle bereits gemacht. Gegenüber der Neuerstellung eines Scripts konnten wir uns durch diese einfache Anpassung eine Menge Arbeit sparen.