











Unser vierter und letzter TechTalkThursday im Jahr 2025 – es war die 26. Veranstaltung unserer Eventreihe – fand am 2. Dezember 2025 um 18 Uhr in unserem Büro statt. Es war das erste Mal ein Dienstag, daher wäre TechTalkTuesday die vielleicht passendere Bezeichnung des Anlasses gewesen. Wie auch immer, wir durften drei externe Referenten begrüssen, die alle spannende Vorträge hielten. Es waren viele Besuchende vor Ort, darunter auch einige interessierte Nine-Mitarbeitende, einige Gäste der Referenten und viele externe Teilnehmende die sich für die Themen Nutanix-Kubernetes-Plattform, RAM xor Downtime und Datenlokalisierung für Applikationsdienste bei Cloudflare interessierten.
Dieser TechTalkThursday wurde auch live auf unserem YouTube-Kanal übertragen, und wir haben uns gefreut, dass auch einige Zuschauende auf dieser Plattform dabei waren. Wie üblich eröffnete Thomas Hug, unser CEO und Gründer, die Veranstaltung mit einer kurzen Einführung, in der er die Tagesordnung des Abends vorstellte, die Referenten ankündigte und die Themen ihrer Vorträge präsentierte. Diesmal waren die drei Referenten Patrick Jundt, Senior Systems Engineer MSP bei Nutanix, Josua Schmid, Engineer und Partner bei Renuo, und Josip Stanić, Solutions Engineer bei Cloudflare.
Nutanix-Kubernetes-Plattform: ein Deep-Dive
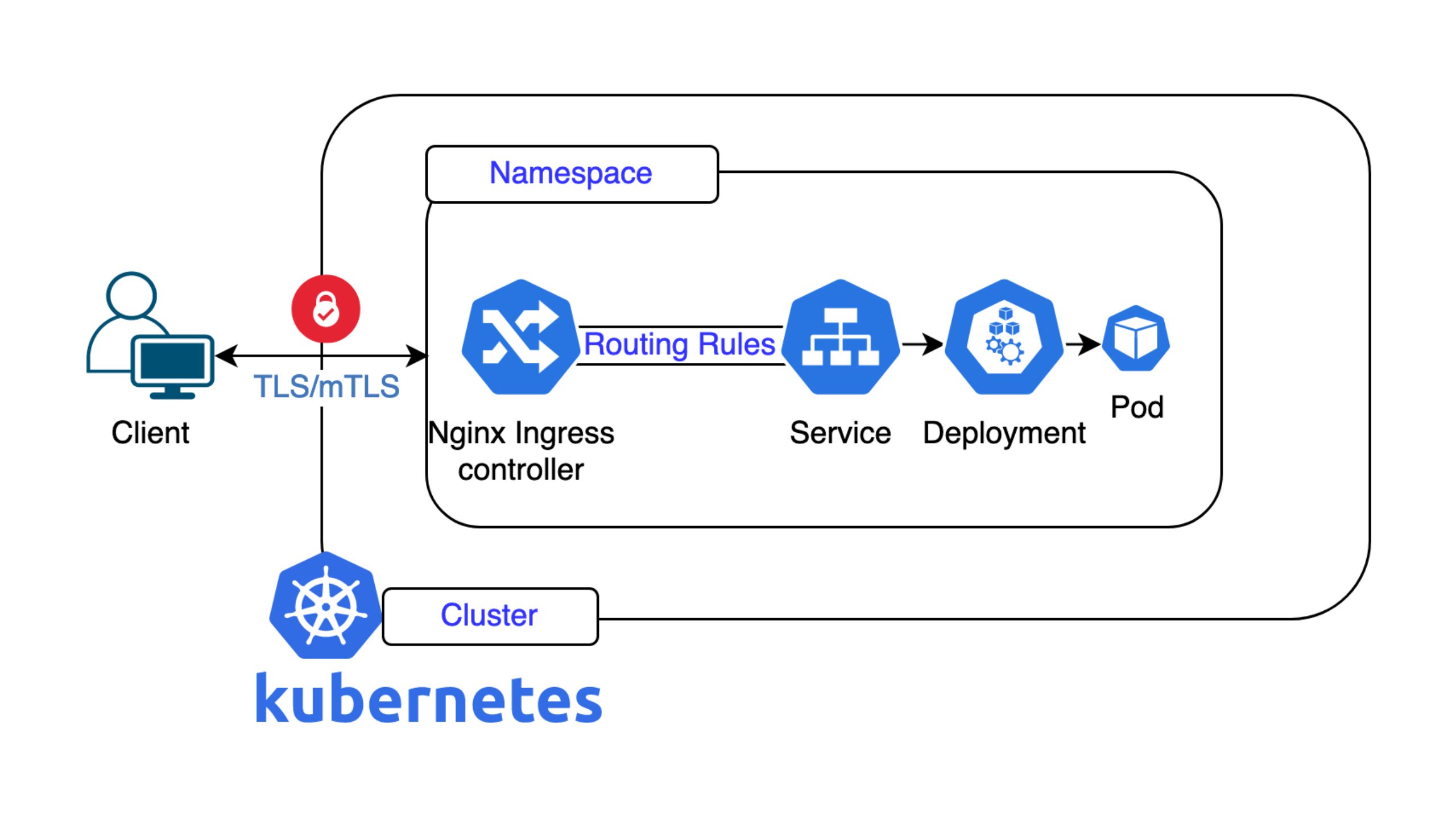
In diesem Vortrag stellte Patrick einen detaillierten technischen Überblick über die Nutanix Kubernetes Platform (NKP) vor und erklärte, wie diese die Bereitstellung, den Betrieb und die Verwaltung von Kubernetes-Umgebungen vereinfacht. Auf der Grundlage seiner langjährigen Erfahrung mit containerisierten Workloads hob er die Herausforderungen der Komplexität von Kubernetes hervor und erläuterte, wie NKP diese durch eine integrierte, unterstützte Plattform löst.
Patrick begann mit einer Würdigung der Leistungsfähigkeit von Kubernetes: Es ermöglicht Containerisierung, Skalierbarkeit, schnellere Bereitstellungen und effiziente DevOps-Workflows. Der Betrieb von Kubernetes in der Produktion ist jedoch alles andere als einfach. Eine vollständige Plattform erfordert zahlreiche Komponenten – Überwachung (Prometheus, Grafana), Protokollierung (Loki), CI/CD-Integration, Kostenmanagement und mehr. Zwar existieren all diese Tools im Open-Source-Ökosystem, doch ist es schwierig, ihre Kompatibilität untereinander aufrechtzuerhalten. So kann beispielsweise ein Prometheus-Update unerwartet die Kompatibilität mit kube-apiserver- oder kubectl-Versionen beeinträchtigen. Hier setzt NKP an.
NKP bietet einen vollständig validierten, integrierten Kubernetes-Stack, der durch den Support von Nutanix unterstützt wird. Anstatt mehrere spezialisierte Ingenieure für die Wartung verschiedener Komponenten zu benötigen, bündelt NKP diese in einer Plattform mit garantierter Kompatibilität und Lebenszyklusmanagement. Patrick betonte, dass dies den Betriebsaufwand erheblich reduziert, sodass sich die Teams auf ihre Arbeitslasten konzentrieren können, anstatt sich um die Wartung der Plattform zu kümmern. Er erklärte auch, wie NKP die Verantwortlichkeiten zwischen Infrastruktur-Administratoren, Plattform-Ingenieuren und Entwicklern mithilfe einer rollenbasierten Zugriffskontrolle aufteilt. Dadurch werden Situationen wie nächtliche Anrufe wegen dringender Bereitstellungen vermieden – Entwickler können Code über GitOps-Prozesse übertragen, die NKP nahtlos über APIs integriert.
Eine zentrale Designüberlegung bei Kubernetes ist die Frage, ob selbstverwaltete Cluster oder separate Management-Cluster verwendet werden sollen. Patrick verglich Architekturen, bei denen die Steuerungsebenen unabhängig voneinander oder zusammen laufen. NKP unterstützt Hochverfügbarkeit an mehreren Standorten: So kann beispielsweise ein Standort ausfallen, ohne dass dies Auswirkungen auf die Workloads an einem anderen Standort hat, da die Workload-Cluster auch dann weiterlaufen, wenn die Managementebene vorübergehend nicht verfügbar ist. NKP verwendet standardmässige Kubernetes-Schnittstellen und APIs, sodass Unternehmen bei Bedarf später die Plattform wechseln können. Ausserdem vereinfacht es gängige Verwaltungsaufgaben durch die Integration von Cluster-APIs und bietet Tools, die komplexe kubectl-Operationen abstrahieren.
Ein grosser Vorteil ist das automatisierte Cluster-Lebenszyklusmanagement. NKP verwaltet die Erstellung von Bootstrap-Clustern, die Installation von API-Komponenten und die Bereinigung – Aufgaben, die sonst umfangreiche manuelle Arbeit erfordern würden. Dazu gehören drei Installationsoptionen: eine benutzerfreundliche Oberfläche, eine erweiterte CLI für detaillierte Konfigurationen (zum Beispiel die Auswahl von Ingress-Controllern) und vollständig manuelle deklarative Konfigurationsdateien für fortgeschrittene Benutzer.
Anschliessend ging Patrick auf private Container-Registries ein und empfahl diese gegenüber öffentlichen Registries für Kubernetes-Cluster in Unternehmen. Öffentliche Images bergen Sicherheitsrisiken, können verändert oder entfernt werden und können nicht in Air-Gapped-Umgebungen verwendet werden. Tools wie Harbor ermöglichen es Unternehmen, geprüfte Images zu speichern und interne Sicherheitsscans durchzuführen. Für die Beobachtbarkeit enthält NKP standardmässig Grafana, Prometheus und Loki und bietet integrierte Metriken, Protokolle und Dashboards, ohne dass eine separate Einrichtung erforderlich ist.
Patrick betonte, wie wichtig es ist, Ressourcenanforderungen und -beschränkungen korrekt festzulegen, um Instabilität zu vermeiden – zu strenge Beschränkungen können Anwendungen wie Tomcat in Absturzschleifen bringen, während zu lockere Einstellungen Ressourcen verschwenden. Abschliessend betonte er, dass für einen erfolgreichen Kubernetes-Betrieb eine angemessene Dimensionierung der Knoten (weniger grosse Knoten gegenüber vielen kleinen Knoten), eine sorgfältige Workload-Planung und vollständige Transparenz über den Zustand des Clusters erforderlich sind – alles Bereiche, in denen NKP integrierte Unterstützung bietet.
RAM xor Downtime
In tIm zweiten Vortrag konzentrierte sich Josua auf die Erfahrungen eines Anwendungsentwicklers mit kleinen Anwendungen, die von der Heroku-Plattform auf eine Kubernetes-basierte Lösung wie Deploio migriert wurden. Er betonte, dass seine Apps «wirklich nicht Facebook» sind und dass die Komplexität, die moderne Container-Orchestrierungssysteme mit sich bringen, für kleinere Nutzer oft die Vorteile überwiegt.
Josuas Anwendungen sind in der Regel klein, wie beispielsweise eine Anwendung, die alle KPIs für 50 % des Zeitarbeitsmarktes verarbeitet und Daten von nur 10 API-Nutzern und zwei GUI-Nutzern aggregiert, wobei politische Entscheidungen auf der Grundlage der Daten getroffen werden. Ein weiteres Beispiel hat 10’000 Anfragen pro Minute, was immer noch «ganz und gar nicht Facebook» ist.
Josua befürwortete das Heroku-Entwicklungsideal, insbesondere wie es um 2007 existierte, bei dem sich der Entwickler fast ausschliesslich auf den Code und das Produkt konzentrieren konnte. Heroku basierte auf der Idee der Einfachheit: Eine App ist nur eine App, und Dinge wie Datenbank, Netzwerk, Lastenausgleich und Protokollierung sind Nebensächlichkeiten, die durch sinnvolle Standardeinstellungen geregelt werden. Das ursprüngliche Ideal umfasste sogar einen Code-Editor im Browser und die Bereitstellung per Knopfdruck, obwohl sich dies später weiterentwickelte. Das Konzept, «einfach auf Speichern klicken, um zu deployen», ist ein zentraler Grundsatz.
Renuo, das eine Schweizer Alternative suchte, hat sich mit uns zusammengetan, um Deploio zu entwickeln, das als «Schweizer Heroku» fungiert. Seitdem hat Renuo fast alle seine 150 Heroku-Apps auf Deploio migriert, das seit einem Jahr ohne grössere Ausfälle in der Produktion läuft.
Trotz der Zuverlässigkeit von Deploio äusserte Josua grosse Frustration darüber, dass Kubernetes-Konzepte in die einfache Entwicklererfahrung «eindringen». Er glaubt, dass die versprochene Magie von Kubernetes, die «Wunderwaffe für alle Probleme», für Nutzer, die nicht in grossem Massstab wie Facebook arbeiten, noch nicht erfüllt wurde.
Seine Hauptkritikpunkte hinsichtlich der Komplexität waren:
- Komplexe Terminologie: Kubernetes hat eine übermässig komplexe Terminologie, die im Gegensatz zum einfachen Modell eines Prozesses steht, der auf einem Port lauscht (wie CGI).
- Unmöglichkeit, Apps umzubenennen: Derzeit können Apps auf Deploio nicht umbenannt werden, ohne sie zu löschen oder zu kopieren, was Josua auf Schwierigkeiten bei der konsistenten Beibehaltung von Labels in Kubernetes-Konfigurationen zurückführt.
- Anhaltende Speicherbeschränkungen: Josua merkte an, dass das ihm vertraute 12-Faktor-App-Modell (bei dem keine Dateien verwendet werden und Objektspeicher wie S3 bevorzugt wird) die Unterstützung persistenter Dateien in der Kubernetes-Umgebung ohne erhebliche Kosten erschwert. Er wies auch auf eine Entwicklung in Rails hin, SQLite mit schnellen SSDs zu verwenden, und betonte, dass die Dateiunterstützung für kleinere Apps, die nicht viel schreiben, relevanter ist.
- RAM versus Ausfallzeit für einzelne Replikate: Das zentrale Thema, das der Präsentation ihren Titel gab, ist der erzwungene Kompromiss für kleine Apps. Bei Apps, die nur ein einziges Replikat ausführen, ist eine Ausfallzeit garantiert, wenn ein Knoten erschöpft ist, da ein neuer Knoten erstellt und die App verschoben werden muss. Um dies zu verhindern, muss eine zweite Replik ausgeführt werden, was eine Verdopplung der RAM-Kosten bedeutet (beispielsweise von 30’000 auf 60’000 pro Jahr), was für kleine Nutzer eine enorme Steigerung darstellt, im Gegensatz zu grossen Anwendungen, bei denen eine Replik nur einen geringen prozentualen Anstieg bedeutet. Die Möglichkeit, eine Replik während einer Knotenverschiebung vorübergehend zu duplizieren, ist kompliziert, da der Anwendungsentwickler möglicherweise nicht damit rechnet, dass zwei Instanzen ausgeführt werden.
Josua schloss mit der Feststellung, dass selbst Heroku sich von dem entfernt, was es grossartig gemacht hat, und mit der Umstellung auf seine Plattform der nächsten Generation zunehmend Ausfallzeiten wie bei Kubernetes erlebt. Die Kernaussage war, dass die Komplexität gross angelegter Lösungen in die Welt der kleinen App-Entwicklung «übergreift», was ihm missfällt. Er forderte Deploio auf, einfacher zu werden und die Erwartungen von Entwicklern wie ihm zu erfüllen.
Datenlokalisierung für Applikationsdienste bei Cloudflare
Die letzte Präsentation von Josip bot einen tiefen Einblick in den Ansatz von Cloudflare zur Datenlokalisierung, der durch die zunehmenden Bedenken der Kunden hinsichtlich Datenschutz und Einhaltung lokaler Gesetze motiviert ist.
Cloudflare betreibt ein Anycast-Netzwerk (auch als «Connectivity Cloud» bezeichnet), das den Datenverkehr möglichst nah am Endnutzer (am Rand) aufnimmt, um eine optimale Leistung und sofortige Sicherheitsdienste zu gewährleisten. Diese Architektur ermöglicht es Cloudflare, DDoS-Angriffe abzuwehren und den Datenverkehr weltweit am Edge zu überprüfen, ohne ihn an einen zentralen Standort zurückzuleiten. Dieser Standardprozess erfordert jedoch eine TLS-Entschlüsselung und -Auslagerung am Edge. In der Standardkonfiguration muss eine Kopie der serverseitigen TLS-Schlüssel des Kunden auf jedem Cloudflare-POP (Point of Presence) weltweit vorhanden sein, um eine Layer-7-Überprüfung und Sicherheitsfilterung zu ermöglichen. Genau dieses Standardverhalten wirft Datenlokalisierungs- und Datenschutzbedenken für Unternehmenskunden auf, die nach technischen Massnahmen zur Durchsetzung der Datenhoheit suchen.
Um diese Probleme zu lösen, bietet Cloudflare die Data Localization Suite (DLS) an, die technische Kontrolle über die drei Kernaspekte der Datenlokalität ermöglicht: wo die Schlüssel gespeichert werden, wo die Entschlüsselung stattfindet und wo die Verbindungsmetadaten gespeichert werden.
- Regionale Dienste: Mit dieser Komponente können Kunden eine bestimmte geografische Region (zum Beispiel Europa, Schweiz) festlegen, in der eine Layer-7-Prüfung und Entschlüsselung erfolgen kann. Wenn ein Benutzer eine Verbindung zu einem POP ausserhalb der konfigurierten Region herstellt, wendet dieser POP nur Layer-3-DDoS-Abwehrtechniken an und leitet den Datenverkehr ungeprüft weiter, bis er die für die vollständige Entschlüsselung zugelassene Region erreicht, was für die Schweiz offiziell unterstützt wird.
- GeoKey-Manager: Damit können Kunden die Region steuern, in der ihre hochgeladenen benutzerdefinierten TLS-Zertifikate (Schlüssel) gespeichert werden und wo die anfängliche Verschlüsselung/Entschlüsselung stattfindet.
- Kunden-Metadaten-Grenze: Eine Funktion, mit der Kunden die Kontrolle über den Speicherort von Datenverkehrsprotokollen und Metadaten haben, wobei die aktuellen Optionen die Europäische Union oder die Vereinigten Staaten sind.
Josip fuhr fort, dass Cloudflare für Kunden, die sicherstellen möchten, dass ihre privaten Schlüssel niemals ihre eigenen Sicherheitsgrenzen verlassen, Keyless SSL als Fallback- oder Primärlösung anbietet.
In dieser Konfiguration hostet der Kunde seine privaten Schlüssel auf seinem eigenen Schlüsselserver, der über die Open-Source-Binärdatei GoKeyless mit einem HSM (Hardware Security Module) verbunden werden kann. Cloudflare speichert niemals den privaten Schlüssel; stattdessen signiert der Schlüsselserver die Sitzungstickets. Cloudflare kann dann weiterhin Layer-7-Schutz (wie WAF und DDoS-Abwehr) unter Verwendung von aus diesem Prozess abgeleiteten Sitzungsschlüsseln durchführen, wodurch sichergestellt wird, dass der Kunde die volle Kontrolle über seinen privaten Hauptschlüssel behält.
Josip schloss mit der Betonung des zentralen Engagements von Cloudflare für den Datenschutz, einschliesslich seiner Investitionen in Datenschutzprotokolle und seiner Politik, Kundendaten nicht zu monetarisieren, wodurch die technischen und vertraglichen Rahmenbedingungen für die Datenkonformität gestärkt werden.r data, reinforcing the technical and contractual frameworks for data compliance.
Möchten Sie auf dem Laufenden bleiben?
Abonnieren Sie unsere YouTube-Kanal und besuchen Sie den Blog unserer Website.