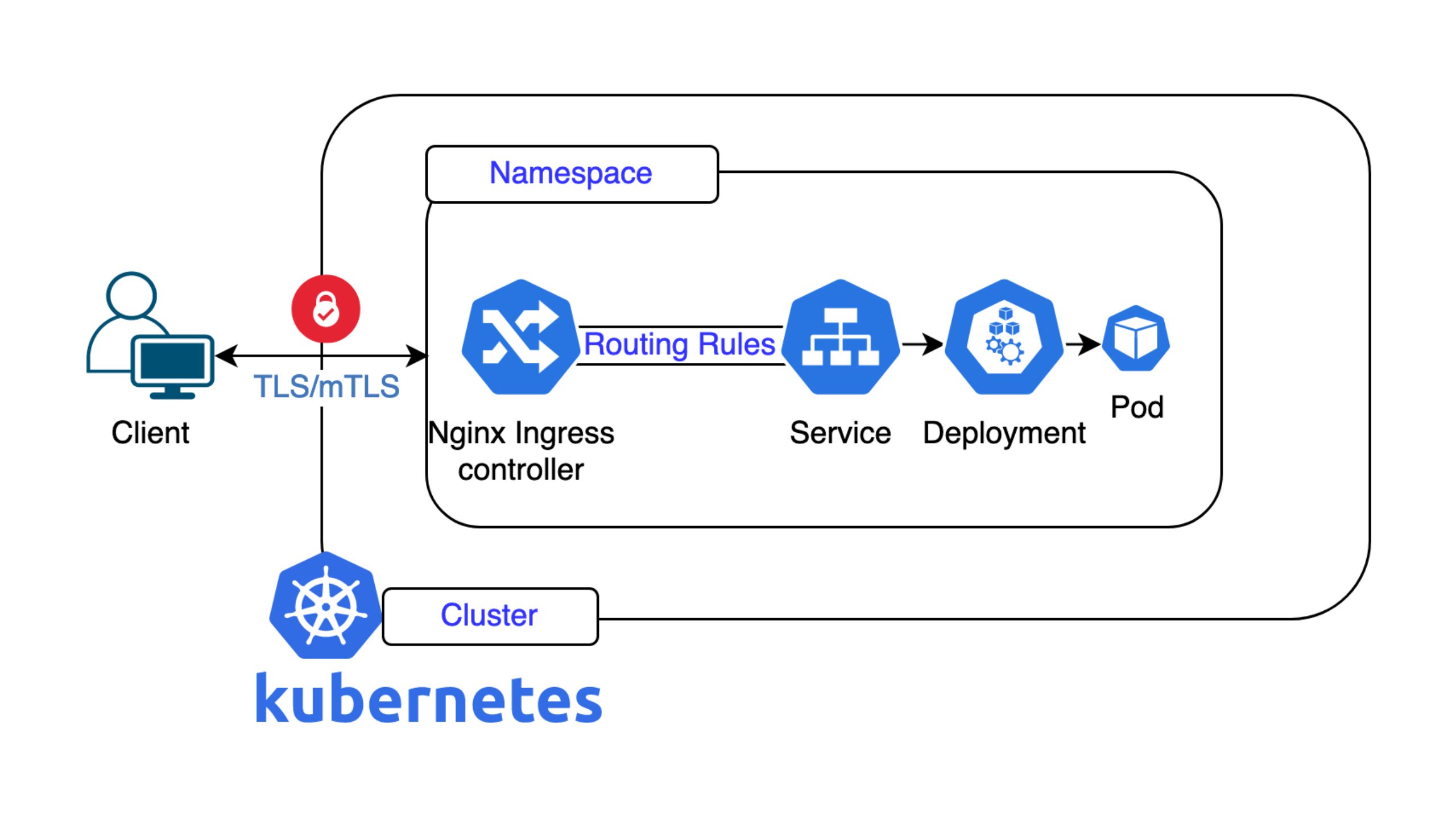












In der heutigen, sich ständig im Wandel befindenden Technologie-Landschaft werden moderne Systeme wie Kubernetes häufig als neueste Innovation des Infrastruktur- und Applikationsmanagements angesehen. Doch auch in der Welt der Containerisierung und der dynamischen Skalierung gibt es Zeiten, in denen diese fortgeschrittenen Technologien mit traditionellen Systemen und Praktiken interagieren müssen.
Einen solchen Bereich stellt das Sicherstellen einer vorhersehbaren Netzwerkkonnektivität dar – besonders, wenn es um ältere Firewalls und externe Dienste geht, die verlangen, dass die Verbindung von einer bestimmten IP-Adresse ausgeht. Da uns bei Nine solche Anforderungen immer wieder begegnen, haben wir uns eine Lösung überlegen müssen: unser neues Feature Static Egress, das wir uns in diesem Artikel näher anschauen wollen.
Warum benötigen wir hierfür eine Lösung?
Als wir unser NKE (Nine Kubernetes Engine) Produkt entwarfen, gehörte zu unseren Hauptzielen sowohl die Automatisierung als auch die Möglichkeit, Self-Service anzubieten. Kubernetes und die dazugehörigen Add-ons bieten bereits eine gute Basis dafür. Je nach Ressourcenbedarf des Clusters, auf dem die Workloads laufen, fügt der Cluster-Autoscaler zum Beispiel Nodes hinzu oder entfernt sie wieder. Etwas, worum sich Kubernetes jedoch nicht von sich aus kümmert, ist die Verwaltung der darunterliegenden Nodes.
Bei unseren VMs führen seit jeher die Updates der installierten Software und der Linux Kernel mithilfe eines Konfigurationssystems und des Package Managers der darunterliegenden Linux-Distribution durch. Das betrifft auch Upgrades von einem grossen Distribution-Release zum nächsten (z. B. von Ubuntu 22.04 auf 24.04), für die viel Vorbereitung und Vorarbeit nötig sind. Als wir NKE einführten, wollten wir diesen Weg nicht gehen und suchten daher nach anderen Lösungen.
Als wir NKE ins Leben riefen, hatten wir glücklicherweise bereits Erfahrungen mit der Verwaltung von Google Kubernetes Engine (GKE) Clustern sammeln können. Dort waren wir sehr zufrieden damit, wie Node-Upgrades durchgeführt werden. In einem GKE Cluster wird die Node-Software selbst nicht in einer bereits laufenden Instanz aktualisiert. Stattdessen werden die Maschinen eine nach der anderen durch neuere, aktualisierte Maschinen ersetzt. Bei der Implementierung dieses Workflows setzen wir auf Flatcar Linux, welches eine rollende Linux-Distribution mit fortgeschrittener Sicherheit bietet. Einer der zusätzlichen Sicherheitsmechanismen ist ein unveränderliches Dateisystem, das eine Veränderung bereits installierter Software nicht zulässt. Dadurch werden Versions- und Konfigurationsabweichungen verhindert.
Doch kehren wir zum Upgrade-Mechanismus selbst zurück. Da beim sequentiellen Upgrade-Workflow eine neue Maschine hinzugefügt wird, bevor die alte entfernt wird, laufen beide einen kurzen Moment lang gleichzeitig. Eine Konsequenz daraus ist, dass beide Nodes unterschiedliche IP-Adressen nutzen müssen, was sich wiederum auf die Workloads auswirkt, die auf dem Kubernetes Cluster laufen. Das liegt daran, dass die ausgehende IP-Adresse für den externen Datenverkehr des Clusters von der IP des Nodes selbst abhängt (vom Workload veranlasster Datenverkehr zu externen Adressen nutzt eine Node Source NAT).
Nachdem wir unseren Node Upgrade-Mechanismus implementiert und eingeführt hatten, fragten einige unserer Kund*innen nach der IP-Adresse ihrer NKE-Cluster-Nodes, da sie diese auf externen Firewalls konfigurieren wollten. Da sich die IP-Adressen der Nodes jedoch im nächsten Wartungsfenster vermutlich wieder ändern würden, konnten sie nicht mehr langfristig bestimmt werden. Selbst wenn sie während der Wartung gleich blieben, bestand immer noch die Möglichkeit, dass die Nutzung von Node Pools, die mithilfe des Cluster-Autoscalers skaliert wurden, zu neuen Nodes mit neuen IP-Adressen führte. Es war daher klar, dass die dynamische Welt von Kubernetes nicht wirklich in die vorhandenen, eher statischen Umgebungen passt.
Eine ganze Zeit lang bestand die einzige Lösung darin, alle NKE Subnetze auf externen Firewalls zuzulassen. Das verringert zwar das Risiko von Angriffen auf externe Dienste, doch meiner Meinung nach ist eindeutig, dass es sich hierbei nicht wirklich um eine zufriedenstellende Lösung handelt. Das Ganze wird noch zusätzlich dadurch kompliziert, dass wir ausserdem mit der Zeit neue NKE Subnetze hinzufügen müssen.
Wie haben wir das Problem gelöst?
Als wir genauer untersuchten, wie dieses Problem gelöst werden kann, wurden wir darauf aufmerksam, dass unser CNI-Anbieter Cilium bereits ein Feature mit dem Namen Egress Gateway anbot. Die dazugehörige Dokumentation beschreibt das Feature wie folgt:
«Das Egress Gateway Feature routet alle IPv4-Verbindungen, die von Pods ausgehen und deren Ziel spezifische CIDRs ausserhalb des Clusters sind, über bestimmte Nodes, die ab diesem Zeitpunkt ‹Gateway Nodes› heissen. Wenn das Egress Gateway Feature eingeschaltet ist und Egress Gateway Regeln vorhanden sind, werden passende Pakete, die den Cluster verlassen, mit ausgewählten, vorhersehbaren IPs maskiert, die mit den Gateway Nodes in Verbindung stehen.»
Dieses Feature löste zwar unser Problem mehr oder weniger, aber es gab noch weitere Punkte, die wir ebenfalls angehen mussten.
Erstens könnte der «Gateway Node» während eines Wartungsfensters einfach verschwinden (da er ersetzt wird), sodass ein anderer Node seine Rolle übernehmen muss. Die IP-Adresse dieses neuen «Gateway Nodes» könnte wiederum von einem ganz anderen Subnetz als die des vorherigen «Gateway Nodes» stammen. Daher war uns klar, dass wir die IP-Adressen bereits vorhandener NKE-Subnetze nicht als Static-Egress-IPs nutzen konnten.
Zweitens muss die IP-Adresse, die als Egress-IP genutzt werden soll, über einen bestimmten Mechanismus auf dem «Gateway Node» konfiguriert werden. Cilium tut das nicht automatisch, sondern verlangt vielmehr, dass dies bereits voreingestellt ist.
Um das erste Problem zu lösen, verwenden wir BGP (Border Gateway Protocol), um unseren Routern die Routen für spezielle, unabhängige Egress-IPs anzukündigen. Den gleichen Mechanismus verwenden wir bereits bei Kubernetes-Services des Loadbalancer-Typen (für eingehenden Datenverkehr) in unseren NKE-Clustern. Daher war es für uns logisch, das gleiche System auch hier anzuwenden. Damit sind die statischen Egress-IPs komplett unabhängig von den Subnetzen, die wir für unsere NKE-Nodes nutzen.
Nachdem wir die Untersuchung dieses Falles abgeschlossen und einige erste Testdurchläufe vorgenommen hatten, wussten wir, was nun zu tun war. Unsere nächste Aufgabe bestand darin, einen Cluster Agent zu entwickeln, der auf den Control-Plane Nodes (von denen wir 3 betreiben) jedes NKE-Clusters laufen kann und einen der Nodes als «Gateway Node» auswählt. Der Agent teilt diesem Node dann ein spezifisches Kubernetes-Label zu, übernimmt alle BGP-Arbeiten, um das richtige Routing für eine ausgewählte statische Egress-IP aufzubauen und konfiguriert diese IP auf dem Node selbst. Wenn der ausgewählte Egress-Node dann während der Wartung gelöscht wird (oder auch einfach aus anderen Gründen nicht mehr funktioniert), sucht sich der Agent einen der anderen vorhandenen Nodes aus und führt eine Neukonfiguration durch. Glücklicherweise gibt es bereits Lösungen für die Auswahl dieses sogenannten «Leaders» (der Leader ist der ausgewählte Egress-Node), die wir bereits in Kubernetes nutzen konnten. Nach einem Monat Arbeit und Tests war der Agent fertiggestellt.
Um die Entwicklung des Static Egress Features abzuschliessen, haben wir dann noch Ciliums «Egress Gateway» integriert, die Konfiguration unseres Agenten in einen Setup-Workflow vorgenommen und ihn über unsere API veröffentlicht. Da Deploio bereits auf NKE basiert, konnte das Static Egress Feature dort einfach bereitgestellt werden. Das Gleiche trifft auf vClusters zu. Sobald die Dokumentation fertig war, konnten wir unseren Kund*innen das Feature anbieten.
Das Feature läuft nun seit einiger Zeit in der Produktionsumgebung und hat sich als zuverlässige Lösung für das Bereitstellen vorhersehbarer Egress-Identitäten erwiesen.