






























































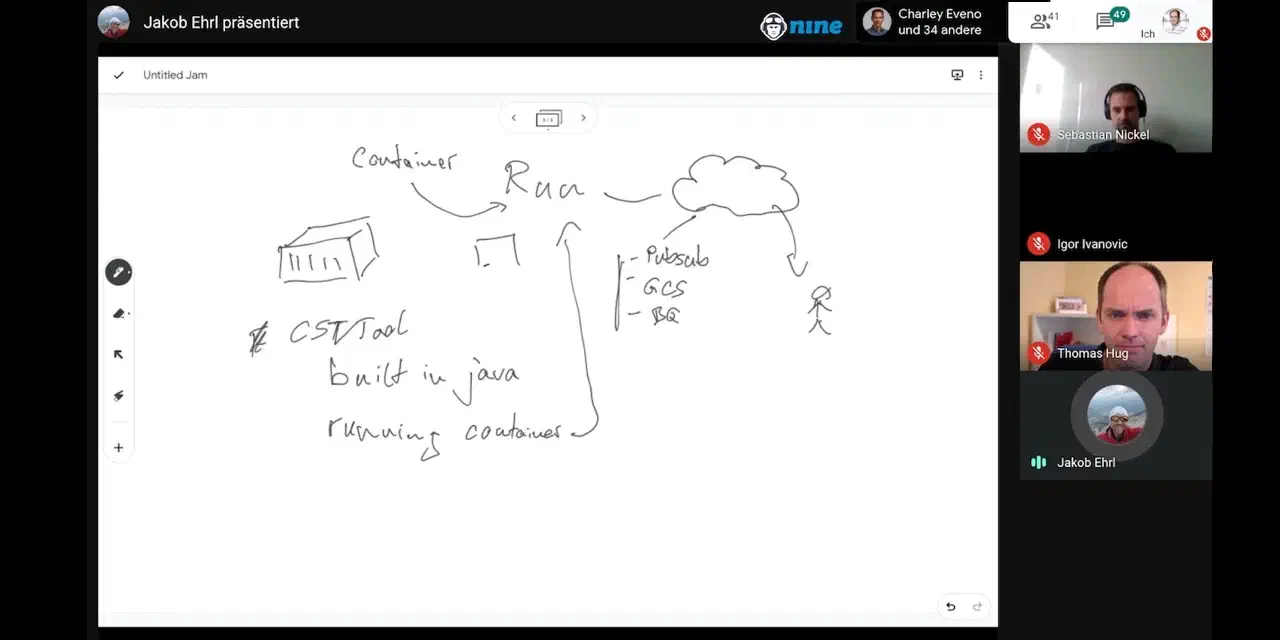





Wenn man mit anderen über die Migration ihrer Anwendungen auf Kubernetes spricht, tauchen oft Fragen zur Datenspeicherung auf:
Verbleiben die Daten in der Schweiz (Datenlokalität)?
Sind die Daten auf dem Speicher verschlüsselt?
Gibt es eine Verschlüsselung während des Übertragens?
Ist es möglich, «grosse Zahl einfügen» Speicherplatz zur Verfügung zu stellen?
Eine Sache, die oft übersehen wird, ist die Frage, wie man auf Daten in einem Kubernetes-Cluster mit mehreren Nodes zugreifen und sie speichern kann und welche Infrastruktur dafür benötigt wird. Da wir hier mehrere Optionen haben, möchte ich dieses Thema näher beleuchten und die Unterschiede erläutern.
Warum muss man sich entscheiden?
Häufig werden Anwendungen direkt auf einem einzigen Server (VM oder Bare Metal) ausgeführt, da die Rechenleistung eines Computers für den jeweiligen Anwendungsfall ausreicht. Wenn noch andere Anwendungen laufen, werden diese entweder auf demselben Rechner oder auf einer anderen einzelnen Instanz betrieben. Das Speichern von Daten ist einfach, da die Anwendung nur auf einer lokalen Festplatte lesen und schreiben muss. Diese Architektur entwickelt sich meist aus historischen und wirtschaftlichen Gründen, da kein Load Balancer oder kompliziertes Cluster-Setup erforderlich ist.
Um nun all diese Anwendungen in einem Kubernetes-Cluster zu konsolidieren (um das Deployment zu vereinheitlichen, mehr Fehlertoleranz zu bieten usw.), sollten die meisten Anwendungen Folgendes unterstützen: den verteilten Betrieb mehrerer Instanzen derselben Applikation (auf verschiedenen Nodes).
Der Grund dafür ist, dass die Nodes in einem Kubernetes-Cluster sehr dynamisch sind. Ein Node kann jederzeit ausfallen (aufgrund eines unerwarteten Ausfalls, einer Wartung, der automatischen Skalierung des Clusters usw.). Wenn wir zum Beispiel Cluster-Upgrades auf unseren NKE-Clustern durchführen, ersetzen wir die Nodes jedes Clusters vollständig, anstatt die Softwarepakete des Betriebssystems auf jeder Instanz zu aktualisieren. Im Falle eines Node-Ausfalls kümmert sich Kubernetes um das Verschieben laufender Anwendungen auf andere Server im Cluster. Dies kann jedoch einige Minuten dauern – wenn dabei nur eine Instanz der Anwendung läuft, kann dies zu kurzen Unterbrechungen führen. Diese Unterbrechungen können sich in einem Wartungsfenster summieren, da jeder Node ersetzt werden muss. Die parallele Ausführung der Anwendung auf mehreren Nodes löst dieses Problem und ist eine der von uns empfohlenen Best Practices.
Eine Herausforderung gibt es jedoch dabei. Wenn jede Anwendungsinstanz Daten nur lokal auf dem Node speichert, auf dem sie läuft, haben andere Instanzen keinen Zugriff auf diese Daten, da sie auf anderen Rechnern betrieben werden. Häufig speichern Webanwendungen von Usern hochgeladene Daten (PDFs, Bilder usw.). Diese Daten müssen nun für alle Anwendungsinstanzen zugänglich sein. Neben unseren Applikationen, die für den Einsatz in einer verteilten Umgebung bereit sein müssen, benötigen wir daher möglicherweise auch ein Speichersystem, auf das verteilte Clients zugreifen können.
Was steht zur Auswahl
Basierend auf dem letzten Abschnitt lässt sich der Zugriff auf das Speichersystem in Kubernetes in zwei Typen unterteilen:
read-write-once (RWO)
read-write-many (RWX)
Der Unterschied ist einfach zu erklären. Wenn auf einen Speicherort nur ein «Writer» (eine Anwendung, die Daten schreiben oder löschen will) auf einen Node und zu einem bestimmten Zeitpunkt zugreifen kann, wird die Zugriffsart RWO genannt. Es kann sein, dass weitere Anwendungen, die auf anderen Nodes laufen, Lesezugriff auf diesen Speicherort erhalten können, aber das hängt vom verwendeten System ab.
Wenn mehrere Applikationen (auf verschiedenen Nodes) Änderungen an den Daten vornehmen müssen, benötigen wir ein Speichersystem, das den RWX-Zugriff unterstützt.

Block Storage
Wenn eine Anwendung auf Partitionen oder ganze Festplatten zugreift, sprechen wir im Allgemeinen von Block Storage (da auf Festplattenblöcke direkt zugegriffen wird). Normalerweise legen wir ein Dateisystem an und stellen es den Anwendungen zur Verfügung, die auf diesem einen Node laufen (Block Storage ist also ein Vertreter der Kategorie «RWO-Zugriff»).
Wenn jemand also eine einzelne Anwendung (z. B. einen Postgres-Datenbank-Pod für die Entwicklung) hat, die ihren eigenen Speicherplatz benötigt, dann sollte derjenige auf Block Storage setzen.
Hierfür gibt es zwei Varianten:
Node Local Block Storage (d.h. eine Festplatte, die an einen bestimmten Node angeschlossen ist)
Remote Block Storage (auf den man über iSCSI, Fibre Channel usw. zugreift)
Remote Block Storage kann im Falle eines Ausfalls oder einer Wartung oft an einen anderen Node angebunden werden und bietet daher Fehlertoleranz auf Maschinenebene. Persistent Node Local Block Storage hingegen ist an einen bestimmten Node gebunden, kann aber sinnvoll sein, wenn Bare-Metal-Server Teil des Kubernetes-Clusters sind und die Anwendung sehr schnellen Zugriff auf den Speicherort benötigt. Allerdings sind alle Anwendungen, die Persistent Node Local Block Storage verwenden, an diesen einen Server gebunden, und im Falle eines Ausfalls kann die Anwendung daher nicht ausgeführt werden. Möglicherweise können in einem solchen Fall spezielle fehlerbehebende Algorithmen in der Anwendung selbst eingesetzt werden (in diesem Fall kommuniziert die Software selbst mit anderen Instanzen und kann sich bei Ausfällen selbst reparieren), aber im Allgemeinen empfehlen wir die Verwendung von Fast Remote Block Storage, da dieser in den meisten Fällen mehr Flexibilität bietet (auch in Bezug auf die Speichererweiterung). Wir betreiben zum Beispiel alle unsere NKE-Cluster auf virtuellen Maschinen und unterstützen standardmässig Fast Remote Block Storage statt Persistent Node Local Block Storage.
Es gibt auch flüchtige Node-Local-Speicherlösungen wie Kubernetes emptyDir oder Googles lokale SSD-Funktion für GKE-Cluster, die als Scratch Space oder temporärer Speicher verwendet werden können.
Im Normalfall zahlt man für die Menge an Block Storage, die man angefordert hat, und nicht dafür, wie viel man davon bereits verbraucht hat.
File Storage
Im Gegensatz zu Block Storage ermöglicht File Storage (wie der Name schon sagt) die gemeinsame Nutzung von Dateien durch mehrere verteilte Clients, indem ein gemeinsames Dateisystem genutzt wird. Anwendungen, die auf Kubernetes laufen, können auf diese Dateien zugreifen, als wären es lokale Dateien. Da fast jede Programmiersprache den Zugriff auf Dateien ermöglicht, ist die Verwendung von File Storage meist die erste Wahl, wenn ein verteilter Lese- und Schreibzugriff erforderlich ist. Lösungen wie NFS, CIFS, CephFS oder GlusterFS implementieren eine derartige Lösung.
Dateien sind in einem Verzeichnisbaum strukturiert, der relativ viele Verzweigungen haben kann. Jede Datei hat eine Payload (die eigentlichen Daten der Datei), benötigt aber zusätzlich Metadaten, die gespeichert werden müssen (Zugriffsrechte, Dateityp usw.). Da mehrere verteilte Clients parallel auf das Dateisystem zugreifen können, müssen zusätzlich Sperrmechanismen vorhanden sein, die eine konsistente Sicht für jeden Client gewährleisten. Dies wird von den verschiedenen Implementierungen unterschiedlich gehandhabt (und hat sich beispielsweise auch bei NFS-Implementierungen im Laufe der Zeit geändert). Ohne zu sehr in die technischen Details zu gehen, bieten File-Storage-Systeme meist eine geringere Leistung im Vergleich zu Block Storage. Allerdings ermöglichen sie auch den RWX-Zugriff, was mitunter eine Voraussetzung für die Verwendung von Kubernetes ist. Ausserdem bieten nicht alle File-Storage-Lösungen volle POSIX-Kompatibilität.
Aus Sicht eines Infrastrukturanbieters ist es nicht so einfach, dynamischen File Storage in einer Kubernetes-Umgebung bereitzustellen und zu betreiben. Früher haben wir einige NFS-Instanzen im Cluster selbst verwaltet, was zu Problemen während der Wartungszeiten führte, in denen alle Nodes ausgetauscht werden. Manchmal blieben Clients stecken und Pods konnten nicht gestartet werden. Hinzu kommt, dass NFS und CIFS seit langem bestehende Lösungen sind, die möglicherweise nicht in die dynamischen Umgebungen von heute passen.
NFSv3 beispielsweise authentifiziert Clients auf Grundlage von IP-Adressen, die in einem Kubernetes-Cluster meist flüchtig sind. NFSv4 kann Clients sicher authentifizieren, aber dafür wird eine Kerberos-Infrastruktur benötigt. CIFS unterstützt einige gute Funktionen, liefert aber auch Windows-spezifische Features wie etwa die Druckerfreigabe, die in einer Kubernetes-Umgebung nicht wirklich benötigt werden. Ausserdem gibt es derzeit zwei NFS-bezogene Kubernetes-Sigs-Projekte, aber keines für CIFS. CephFS ist sehr vielversprechend in Bezug auf Funktionen und Skalierbarkeit, aber die Verwaltung ist sehr komplex (auch wenn rook diese Situation bereits verbessert hat). Als wir vor einigen Jahren noch Openshift-Cluster betrieben haben, verwendeten wir frühe Versionen von GlusterFS, was damals viele Probleme mit Konsistenz und Verfügbarkeit verursachte.
Die Bereitstellung automatischer Sicherungen und Wiederherstellungsmöglichkeiten für File-Storage-Lösungen in einer Kubernetes-Umgebung kann eine zusätzliche Herausforderung darstellen.
Insgesamt sind File-Storage-Lösungen mit einem höheren Preis verbunden, da ihr automatisierter Betrieb einen erheblichen Entwicklungsaufwand erfordert. Wir stellen einen RWX-Speicher in unseren NKE-Clustern bereit, der durch eine NFS-Lösung unseres Infrastruktur-Anbieters unterstützt wird.
Object Storage
Neben den eben erwähnten File-Storage-Lösungen erfreut sich Object Storage zunehmender Beliebtheit, da diese Speicherart ebenfalls einen verteilten Lese- und Schreibzugriff ermöglicht. Anstelle von Dateien werden die Daten in Objekten gespeichert, die eine eindeutige ID in einem «Flat Namespace» (Bucket) haben. Jedes Objekt ist ausserdem mit Metadaten versehen (sodass eine Suche möglich ist).
Der Zugriff auf die Objekte erfolgt über HTTP-basierte Protokolle, wobei Amazons S3 das beliebteste ist (da es von Amazon entwickelt wurde). Diese Art des Zugriffs unterscheidet sich stark von Lösungen, die auf File Storage basieren. Es gibt kein gemeinsam genutztes Dateisystem mehr, das an den Container übergeben wird. Das zugrundeliegende Betriebssystem oder der Cluster-Orchestrator sind nicht mehr beteiligt am Datenzugriff beteiligt. Stattdessen greift die Anwendung selbst über Bibliotheken auf das Object-Storage-System zu. Dies bietet viel Flexibilität, kann aber auch Änderungen am Quellcode der Anwendung bedeuten. Diese Codeänderungen sind auch der Grund dafür, dass einige Anwendungen nicht auf Object Storage setzen. Die Implementierung wäre einfach zu viel Arbeit.
Wenn eine Anwendung jedoch Object-Storage-Lösungen nutzen kann, bringt dies einige grossartige Vorteile mit sich. Hier einige Beispiele:
Pay-what-you-use-Modell: es wird nur der genutzte Speicherplatz berechnet (plus Gebühren für API-Aufrufe und/oder verwendete Bandbreite)
Praktisch unbegrenzter Speicher (benötigter Speicherplatz muss nicht vordefiniert werden)
Verschiedene Richtlinieneinstellungen ermöglichen die Kontrolle der Zugriffsberechtigungen für Buckets und der darin enthaltenen Objekte auf Basis einzelner Benutzer (die durch «Zugriffsschlüssel» identifiziert werden)
Write-once-read-many Buckets (WORM): Daten, die einmal geschrieben wurden, können nicht mehr gelöscht oder überschrieben werden. Richtlinien können dafür sorgen, dass Daten nach einer bestimmten Zeit automatisch gelöscht werden.
Datenzugriff von überall: Auf Buckets und Objekte kann üblicherweise von überall auf der Welt zugegriffen werden, unabhängig davon, wo die Anwendung läuft. Eine deployte File-Storage-Lösung ist möglicherweise nicht von ausserhalb des Kubernetes-Clusters zugänglich.
Die Verwendung von HTTPS bietet Verschlüsselung bei der Übertragung
Meist unabhängig vom Anbieter: Man kann einfach zu einem anderen Anbieter wechseln, sofern das Object-Storage-Protokoll dasselbe ist (und man keine sehr anbieterspezifischen Funktionen nutzt)
Aber es gibt auch einige Nachteile bei Object Storage und dessen Implementierungen. Objekte können nur als Ganzes geschrieben werden. Das bedeutet, dass ein Objekt nicht geöffnet werden kann, um es zu ergänzen (wie es bei File Storage möglich ist). Man müsste das gesamte Objekt herunterladen, die Daten in der Anwendung anhängen und alle Daten erneut hochladen. Der Zugriff auf Object Storage ist oft langsamer als auf File Storage, sodass Anwendungen, die einen schnellen Zugriff auf Daten benötigen, möglicherweise zwischengespeichert werden oder auf eine File-Storage-Lösung zurückgreifen müssen. Um den Zugriff auf Object-Storage-Systeme zu beschleunigen, sollten die Anfragen nach Möglichkeit parallel erfolgen. Es gibt auch Unterschiede im Funktionsumfang (und der Qualität) von Object-Storage-Lösungen, die den Zugriff über das gleiche Protokoll ermöglichen.
Für unsere Kundinnen und Kunden bieten wir eine S3-kompatible Object-Storage-Lösung, gehostet in Schweizer Rechenzentren.
Was soll ich also verwenden?
Wenn die Anwendung nur aus einer einzigen Instanz besteht und nur selbst Lese- und Schreibzugriff benötigt, sollte ein schneller Block Storage die Wahl sein. Er ermöglicht im Falle eines Ausfalls ein Failover auf einen anderen Node und bietet eine gute Leistung.
Wenn verteilte Lese- und Schreibzugriffe benötigt werden, bevorzugen wir die Verwendung von Object Storage gegenüber File Storage (wenn dein Anwendungsfall dies zulässt). Auch wenn die jeweilige Anwendung Object Storage noch nicht unterstützt, könnte sich eine Implementierung dieser auf lange Sicht lohnen. Die Verwendung von Objekten ermöglicht einfach mehr Flexibilität und bietet oft auch mehr Funktionen.
Bildquelle Featured Image: Intelligent CIO
