











Neben unserem normalen TechTalkThursdays am Abend haben wir neue Zeiten während des Mittagessens und um 08:00 Uhr morgens ausprobiert. Keine der beiden Zeiten erwies sich als besser als die Abendtermine, da wir nicht die gleiche Anzahl von Teilnehmern hatten.
Wir nutzen diesen Artikel, um die Themen von Demian Thoma und Daniel Lorch zusammenzufassen.
Wie ein Titan unsere Cloud-Überwachungsinfrastruktur stärkt
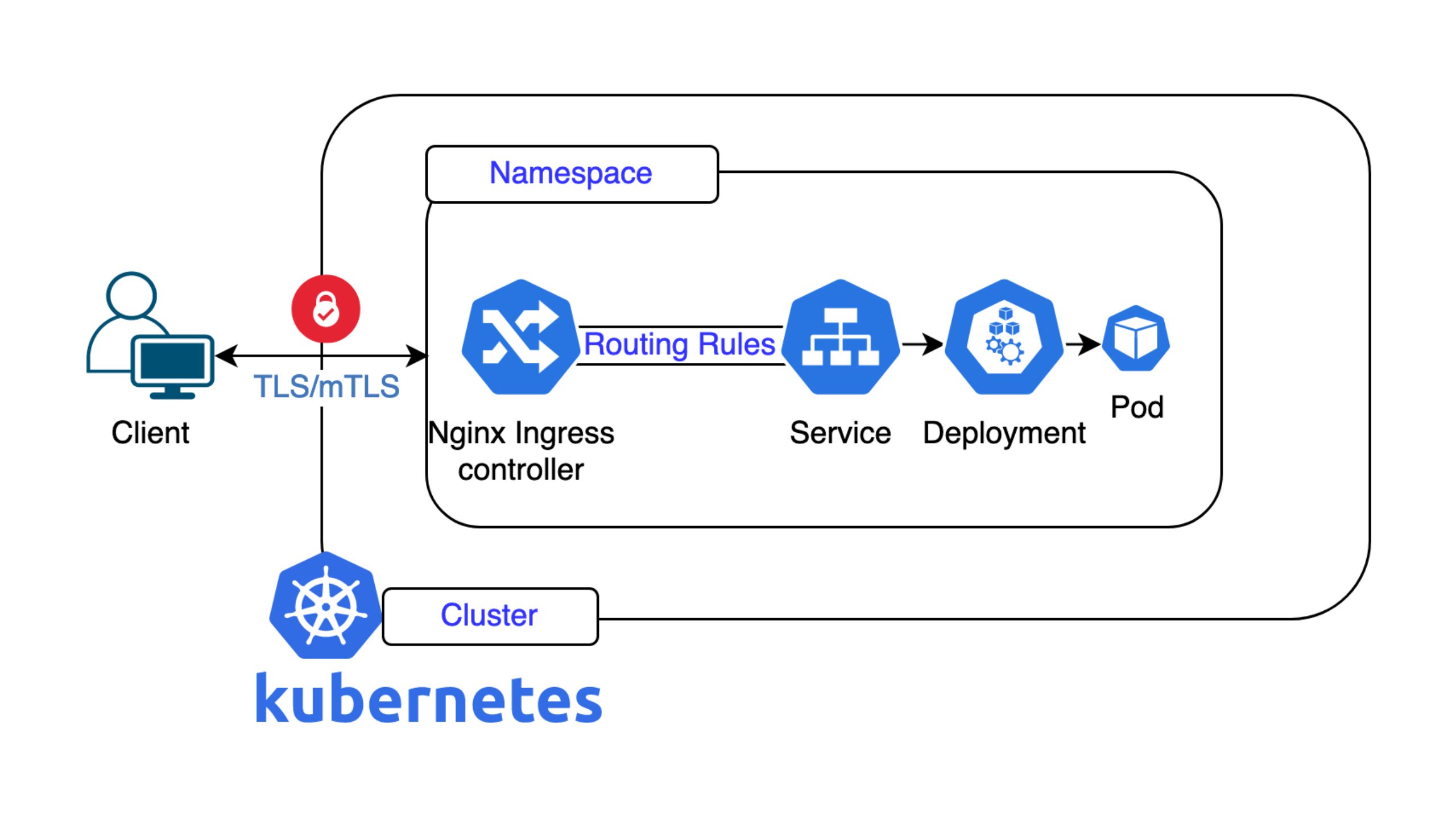
Nine hostet und verwaltet Tausende von Servern für seine Kunden. Kürzlich hat das Unternehmen eine neue Überwachungslösung eingeführt, die auf den Open-Source-Tools rund um Prometheus basiert. Demian Thoma von Nine spricht darüber, wie Nine seine neue Überwachungslösung implementiert hat und wie sie ihnen einen besseren Einblick in ihre Infrastruktur ermöglicht hat.
Vor dem Wechsel zu Prometheus hat Nine Nagios verwendet. Durch den Wechsel des Monitoring-Stacks konnte das Unternehmen die Einrichtung vereinfachen, mehr Einblicke in seine Dienste erhalten und einen separaten Analyse-Stack für die Infrastruktur entfernen.
Site Reliability Engineering: Was du über Service Level Indicators, Service Level Objectives und Error Budgets wissen musst
Was bedeutet Zuverlässigkeit für dich? In seinem Vortrag bekräftigt Daniel Lorch die Behauptung, dass Zuverlässigkeit die wichtigste Eigenschaft eines jeden Systems ist. Allerdings müssen die Dienste gerade zuverlässig genug sein, um die Nutzer zufrieden zu stellen – eine zu hohe Investition in die Zuverlässigkeit führt zu höheren Kosten (Entwicklungszeit und Infrastruktur) ohne zusätzlichen Nutzen. Zu geringe Investitionen hingegen führen zu unzufriedenen Nutzern.
Wie bestimmst und vereinbarst du, was „zuverlässig genug“ für deine Dienste und dein Unternehmen ist? Site Reliability Engineering bietet Werkzeuge und Konzepte, um diese Diskussion zu formalisieren, insbesondere:
- Service-Level-Indikatoren (SLIs): eine Überwachungskennzahl, die das Ziel eines Benutzers angibt
- Service Level Objectives (SLOs): ein Ziel auf einem SLI, das, wenn es knapp erreicht wird, die Benutzer zufrieden stellt
- Fehlerbudgets: die maximale Zeitspanne, in der das System ohne vertragliche Konsequenzen ausfallen kann. Es ist der Rest / die Umkehrung des SLO
Schau dir den 30-minütigen Vortrag unten an, um mehr über diese Konzepte zu erfahren und zu sehen, wie ein Beispiel-SLI/SLO für eine fiktive Spielplattform definiert wird. Links zu weiteren Informationen werden am Ende des Vortrags bereitgestellt.
Bei dieser Gelegenheit möchten wir unseren Referenten erneut für ihre Präsentation danken!