











Unser zweiter TechTalkThursday in diesem Jahr war die Nummer 24 der Veranstaltungsreihe und fand am 5. Juni 2025 um 18 Uhr in unserem Büro statt. Wir freuten uns, drei externe Referenten begrüssen zu dürfen, die alle sehr spannende Vorträge hielten. Es waren fast 40 Personen vor Ort, davon einige interessierte Nine-Mitarbeitenden, ein paar Gäste der Referenten und viele externe Teilnehmende, die sich für die Themen menschenzentrierte KI, Chatbots, Large Language Models und Auth interessierten.
Auch dieser TechTalkThursday wurde wieder live auf YouTube gestreamt und wir haben uns gefreut, einige Zuhörende auch auf dieser Plattform «sehen» zu dürfen. Wie üblich eröffnete Thomas Hug, CEO und Gründer von Nine, die Veranstaltung mit einer kurzen Einführung, in der er den Ablauf des Abends präsentierte, die Redner vorstellte und die Themen ihrer kommenden Vorträge aufzeigte. Diesmal waren die drei Referenten Fabio Duò, CEO der freihandlabor GmbH und Gründer von PeakPrivacy, Florian Schottmann, CTO von Supertext, und Warren Parrad, CTO von Authress.
Menschenzentrierte KI oder von der Lösungsfindung zur Befähigung: die Reise von PeakPrivacy
In seiner Session erörterte Fabio Duò den Weg seines Unternehmens von der Entwicklung KI-gesteuerter Lösungen hin zu einem menschenzentrierten Ansatz für künstliche Intelligenz. Er ist der Gründer von freihandlabor, einem 2009 gegründeten Softwareentwicklungsunternehmen, das auch ein Produkt namens PeakPrivacy entwickelt hat. Das Unternehmen unterstützt in erster Linie Start-ups durch die Entwicklung von Webanwendungen und die Bereitstellung technischer Partnerschaften und hat sich im Laufe der Zeit intensiv mit maschinellem Lernen und KI-Lösungen beschäftigt.
Anfänglich konzentrierte sich der Ansatz auf die Verwendung von KI zur Automatisierung von Aufgaben wie Chatbots und Assistenten, die häufig von Startup-Kund*innen angefordert wurden. Fabio stellte jedoch schnell fest, dass diese Systeme in der Regel keinen echten Mehrwert lieferten – Chatbots führten beispielsweise häufig zu schlechten Nutzererfahrungen. Das Team erkannte, dass die einfache Einbettung von KI in Prozesse in vielen Fällen nicht effektiv funktionierte, was sie dazu veranlasste, ihren Ansatz zu überdenken.
Ein Wendepunkt kam dann, als freihandlabor einen Bewerbungsschreiben-Generator für NGOs entwickelte, die sich bei philanthropischen Geldgebern bewerben. Das Tool nutzte eine umfangreiche Systemabfrage und strukturierte Daten, um individuelle Anschreiben zu erstellen. Obwohl es technisch gut funktionierte, stellten die Nutzer fest, dass die generierten Anschreiben keine persönliche Note hatten und oft manuell angepasst werden mussten – was die Grenzen der automatischen Inhaltserstellung deutlich machte.
Fabio betonte, dass die meisten KI-Tools, selbst die als «Agenten» angepriesenen, letztlich auf ausgefeilten System-Prompts aufbauen – einer Textdatei, die das Verhalten der KI steuert. Er fügte an, dass diese Tools oft besser funktionieren, wenn Fachexpert*innen und nicht KI-Ingenieure die Prompts erstellen. Es hat sich gezeigt, dass es effizienter ist, Profis vom Fach zu schulen, um effektive Prompts zu schreiben, als KI-Spezialist*innen über die Bedürfnisse von Nischenunternehmen zu unterrichten.
Diese Erkenntnis deckt sich mit den jüngsten Erkenntnissen von Y Combinator, das sich zunächst für völlig autonome KI-Agenten einsetzte. Später räumte Y Combinator ein, dass solche Agenten aufgrund der unterschiedlichen Anforderungen oft nicht für verschiedene Kund*innen skalierbar sind. Die Anpassung von Eingabeaufforderungen für jeden Anwendungsfall führt zu einem erheblichen Mehraufwand und macht KI-Unternehmen oft zu Beratungsunternehmen, was den Skalierungszielen von Tech-Startups zuwiderläuft.
Um dieses Problem zu lösen, plädierte Fabio für die Befähigung der Kund*innen, ihre eigenen KI-Lösungen zu entwickeln und zu pflegen. Sein Team entwickelte ein «Botschafterprogramm» und Onboarding-Workshops, um Mitarbeitenden beizubringen, wie sie KI-Agenten erstellen und in ihre Arbeitsabläufe integrieren können. So können beispielsweise die Mitarbeitenden von Schweizer KMUs, die im Kundensupport tätig sind, Antworten mit einer kleinen Anzahl gut gestalteter Aufforderungen automatisieren, die auf häufige Anfragen zugeschnitten sind.Die Entwicklung von freihandlabor umfasste auch die Einführung von PeakPrivacy, einem OpenAI-Klon, der auf unseren Schweizer Servern bei Nine gehostet wird und Open-Source-Modelle wie Mistral und DeepSeq verwendet. Die Infrastruktur ist darauf ausgelegt, den Datenschutz zu wahren, indem die Modelle vierteljährlich ausgetauscht werden und vorgefertigte Modelle ohne Feinabstimmung verwendet werden.
Abschliessend zeigte Fabio (s)eine pragmatische, zugängliche KI-Strategie, die darauf abzielt, die Benutzer*innen mit dem Wissen und den Werkzeugen auszustatten, mit denen sie ihre eigenen Lösungen entwickeln können. Anstatt eine vollständige Automatisierung oder generische KI-Plattformen anzustreben, liegt der Schwerpunkt auf dem Erreichen von 80% Effektivität durch personalisierte, prompt-basierte Systeme. Von dort aus kann die Automatisierung selektiv skaliert werden. Diese Philosophie unterstreicht die Verlagerung weg von technikzentrierter Innovation hin zu menschenzentrierter Befähigung bei der Einführung von KI.
Jenseits von Chatbots: Wie grosse Sprachmodelle für gezielte Anwendungsfälle genutzt werden
In seiner Präsentation untersuchte Florian Schottmann, CTO von Supertext, die Möglichkeiten und Grenzen von grossen Sprachmodellen (LLMs) und argumentierte, dass Chatbots wie ChatGPT zwar leistungsfähig sind, aber keine Einheitslösungen darstellen. Supertext, ein Unternehmen für Sprach-KI, das sich auf Übersetzungen spezialisiert hat, kombiniert technisches und linguistisches Fachwissen, um effektivere KI-gestützte Schnittstellen für bestimmte Anwendungsfälle zu entwickeln.
Florian sprach zunächst ein weit verbreitetes Missverständnis an: LLMs werden mit Chatbots gleichgesetzt. LLMs wie GPT sind die grundlegende Technologie hinter Chatbots, können aber auch auf viele andere Arten angewendet werden. Diese Modelle werden auf umfangreichen, aber endlichen Datensätzen trainiert, um das nächste Wort in einer Sequenz vorherzusagen, wobei iterative Optimierungstechniken zum Einsatz kommen. Sie sind jedoch von Natur aus unvollkommen und durch ihre Trainingsdaten begrenzt, was zu einem Phänomen namens «Halluzinationen» führt – Output, der plausibel klingt, aber faktisch falsch oder erfunden ist.
Ein Hauptproblem, das Florian hervorhob, ist die generische Schnittstelle von ChatGPT, die zwar vielseitig ist, aber bei gezielten oder anspruchsvollen Anwendungen oft ineffizient wird. Bei Übersetzungsworkflows – dem Kernbusiness von Supertext – sind beispielsweise kontextuelle Genauigkeit, Konsistenz und die Fähigkeit, Expertenfeedback einzubeziehen, entscheidend. Er veranschaulichte, wie massgeschneiderte Schnittstellen in diesen Situationen besser abschneiden als allgemeine Chatbots. In seinem Beispiel kontrastierte er den generischen, auf Eingabeaufforderungen basierenden Ansatz von ChatGPT mit der personalisierten Übersetzungsplattform von Supertext, die die Sprachauswahl rationalisiert und eine Expertenvalidierung ermöglicht, wodurch Fehler reduziert und die Benutzerfreundlichkeit verbessert werden.
Er sprach auch über das Instruktionstuning, eine Technik, die Basismodelle dazu bringt, Gesprächsanweisungen zu befolgen, indem sie ihnen Beispiele für hilfreiche Antworten zeigt. Dies verbessert zwar die Interaktion mit dem User, beseitigt aber nicht das Risiko von Halluzinationen und garantiert nicht, dass das Modell spezielle Aufgaben ohne zusätzlichen Kontext oder Aufsicht versteht.
In dem Vortrag wurde nachdrücklich dafür plädiert, massgeschneiderte Schnittstellen oder KI-gestützte Produkte zu entwickeln, die auf die spezifischen Bedürfnisse der Nutzer*innen eingehen, anstatt sich auf allgemeine Tools zu verlassen. Beim Programmieren und Übersetzen brauchen die Nutzer*innen oft mehr als einen Chatbot – sie brauchen Agenten, die mit lokalen Umgebungen interagieren (z. B. Dateien erstellen, konsistente Terminologie beibehalten) und Systeme, die eine solide Qualitätssicherung bieten.
Florian betonte auch, wie wichtig es ist, dass der Mensch an der Entwicklung beteiligt ist. KI-generierte Ergebnisse sollten überprüft werden, insbesondere in Kontexten, die Präzision erfordern, wie z. B. Rechts- oder Finanztexte. Er teilte mit, dass Supertext Schulungsprogramme für Kund*innen anbietet, die ihnen helfen, sowohl die Stärken als auch die Grenzen von KI-Tools zu verstehen. Dies verhindert Missbrauch – wie etwa ein übermässiges Vertrauen in die Automatisierung – und fördert die durchdachte Integration von KI in Arbeitsabläufe.
Anschliessend ging er auf den Datenschutz und die Datensicherheit ein und wies darauf hin, dass Supertext seine Modelle in der Schweiz hostet – unter Verwendung unserer Nine-Infrastruktur – und die Datenschutzstandards einhält. Daten von Nutzer*innen werden gelöscht, sofern sie nicht ausdrücklich für die Modellverbesserung aufbewahrt werden, wodurch die Einhaltung strenger Datenschutzerwartungen, insbesondere von Firmenkund*innen, gewährleistet wird.Abschliessend war Florians zentrale Botschaft, dass der Erfolg von KI-gestützten Lösungen nicht vom Chatbot selbst abhängt, sondern von der Schnittstelle, dem Kontextbewusstsein, dem Expertenfeedback und der Ausrichtung auf spezifische Nutzerbedürfnisse. Auch wenn ChatGPT und ähnliche Tools beeindruckend sind, kann der Aufbau fokussierter, domänenspezifischer Lösungen praktischere und effizientere Ergebnisse liefern. Seine Erkenntnisse unterstrichen einen wachsenden Konsens: Der wahre Wert von KI kommt zum Vorschein, wenn sie durchdacht in die einzigartige Struktur jeder Aufgabe und Branche eingebettet wird..
Was genau ist eigentlich «Auth»?
In seinem energiegeladenen und humorvollen Vortrag brachte Warren Parrad, CTO von Authress, die oft verwirrende Welt der Authentifizierung («Auth») auf den Punkt, indem er sich auf die Grundlagen und nicht auf die unzähligen Protokolle (OAuth, SAML, OpenID usw.) konzentrierte. Sein Ziel war es, Entwickler*innen ein grundlegendes Wissen darüber zu vermitteln, wie moderne Authentifizierungssysteme funktionieren, damit sie sichere und effektive Authentifizierungsabläufe in ihren Anwendungen implementieren können.
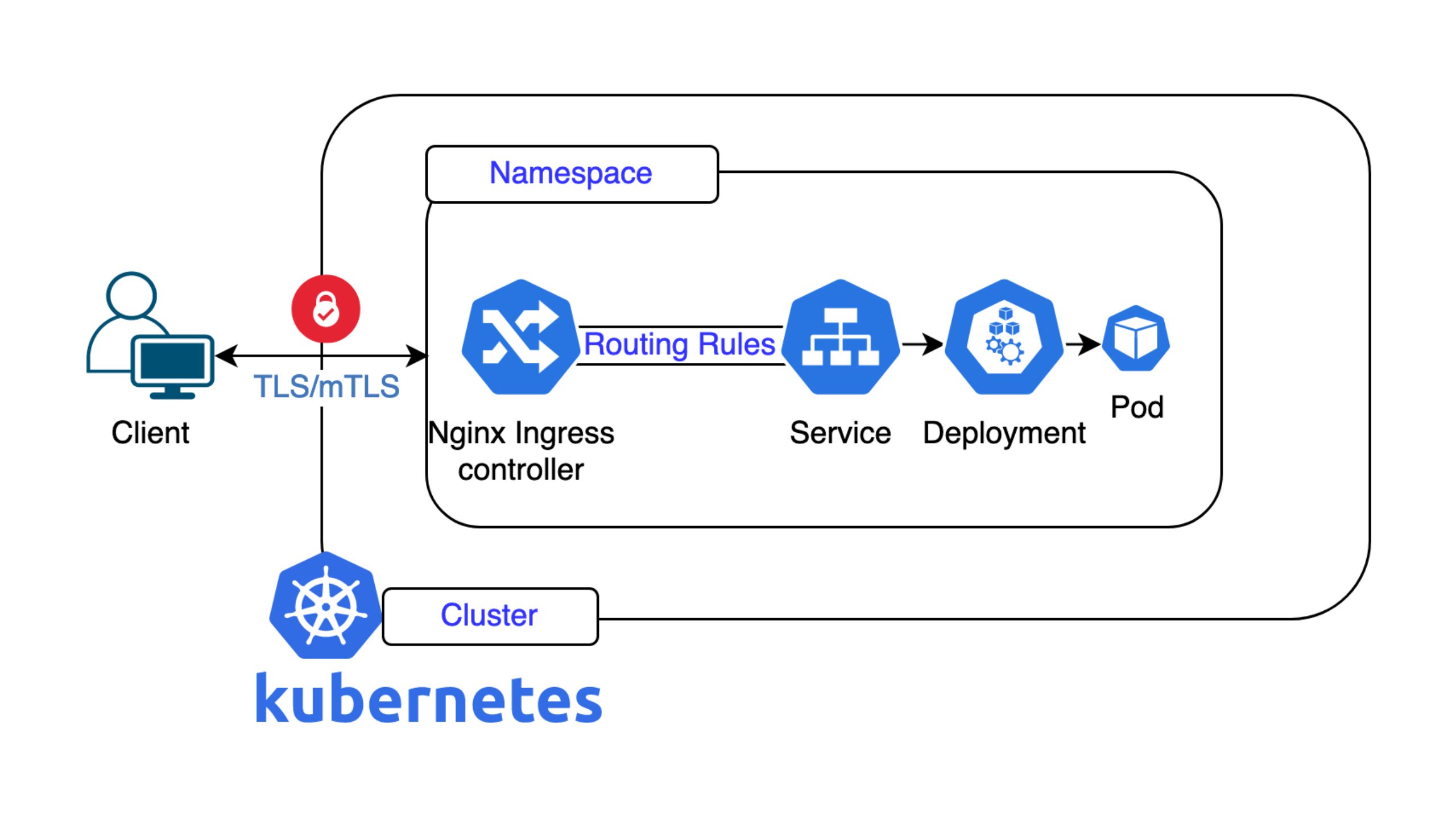
Das Herzstück der Authentifizierung ist das Token, insbesondere das JSON Web Token (JWT). JWTs werden überall in modernen Systemen verwendet, um die Identität eines Users darzustellen. Sie enthalten Metadaten, Benutzerinformationen und eine kryptografische Signatur, um Manipulationen zu verhindern. Wichtig ist, dass JWTs nicht verschlüsselt sind und von jedermann gelesen werden können, was eine Überprüfung der Signatur unerlässlich macht. Jedes System, das ein JWT empfängt, muss dessen Authentizität mithilfe eines bekannten öffentlichen Schlüssels bestätigen, um Nachahmungen oder Angriffe zu verhindern.
Warren skizzierte den grundlegenden Authentifizierungsablauf: Ein*e Benutzer*in versucht, auf geschützte Ressourcen zuzugreifen, klickt auf eine Anmeldeschaltfläche, wird an einen Identitätsanbieter (z. B. Google, Facebook) weitergeleitet und erhält nach erfolgreicher Überprüfung ein JWT. Dieses Token wird clientseitig gespeichert (z. B. im lokalen Speicher) und bei nachfolgenden Anfragen über den Authorization Bearer <token> HTTP-Header gesendet. Er betonte, dass Token niemals in URLs oder beliebigen Headern gesendet werden sollten.
Er kritisierte auch, dass man sich zu sehr auf grosse Sprachmodelle (LLMs) verlässt, um Login-Komponenten zu erstellen, ohne die zugrunde liegende Architektur zu verstehen. Eine wichtige Botschaft lautete: Man sollte wissen, was man baut, bevor man anfängt. Warren ermutigte die Entwickler*innen, klare Ziele zu definieren – wie die sichere Identifizierung von Benutzer*innen und die Überprüfung ihrer Identitäten –, bevor sie sich an den Code machen.
Als Nächstes ging er auf häufige Fallstricke bei Authentifizierungsschnittstellen ein, wie zum Beispiel das Verlassen auf einen einzigen föderierten Anbieter, veraltete Methoden wie CAPTCHAs oder Sicherheitsfragen oder schlecht implementierte Anmeldebildschirme. Er empfahl die Verwendung bewährter Frameworks, Open-Source-Lösungen oder SaaS-Plattformen, um sichere, konforme und benutzerfreundliche Authentifizierungssysteme zu entwickeln.
Ein grosser Teil des Vortrags war dem Token Lifecycle Management gewidmet. JWTs laufen ab, daher sollte die stille Authentifizierung (nicht Refresh-Tokens) verwendet werden, um sie ohne Benutzerinteraktion zu erneuern. Refresh-Tokens, so argumentierte Warren, werden falsch verstanden und oft falsch eingesetzt. Ihr richtiger Anwendungsfall ist die Delegation, das heisst die Gewährung des Zugriffs eines Systems auf die Daten eines anderen Systems im Namen eines Users (zum Beispiel eine App zur gemeinsamen Nutzung von Fotos, die auf das Google Drive eines Benutzers zugreift).
Was den Token-Widerruf betrifft, so behauptete er kühn, dass dieser in der Regel unnötig und kontraproduktiv sei. Da JWTs in sich geschlossen sind und die Identität repräsentieren, ist ihre Ungültigmachung nach Ablauf der Gültigkeit in der Regel ein Zeichen für eine mangelhafte Architektur. Er plädierte stattdessen dafür, Sitzungsdaten zu widerrufen oder Berechtigungen überhaupt nicht in Token einzubetten.
Anstelle von Berechtigungen in JWTs betonte Warren die Autorisierung als separates Anliegen. Er führte eine ressourcenbasierte Zugriffskontrolle ein, bei der bestimmte Berechtigungen an bestimmte Ressourcen gebunden sind (beispielsweise kann ein User nur seine eigenen Fotos verwalten). Dieser Ansatz setzt das Prinzip der geringsten Privilegien durch und verbessert die Sicherheit durch die Begrenzung des Zugriffsbereichs.
Darüber hinaus kritisierte er komplexe Sicherheitssysteme, die durch unnötige Funktionen zusätzliche Risiken bergen, und warf den grossen OAuth-Anbietern (Apple, Microsoft) vor, auf inkonsistente Weise von den Standards abzuweichen, was die Implementierung erschwert. Abschliessend entmystifizierte Warren die Authentifizierung, indem er sich auf die Kernprinzipien konzentrierte: kluge Verwendung von JWTs, Implementierung sauberer und benutzerfreundlicher Login-Flows, Trennung von Authentifizierung und Autorisierung und Minimierung der Komplexität, um Schwachstellen zu reduzieren. Sein Vortrag bot sowohl konzeptionelle Klarheit als auch praktische Anleitungen für die sichere Verwaltung von Benutzeridentitäten in modernen Anwendungen.
Möchten Sie auf dem Laufenden sein?
Abonnieren Sie unsere YouTube-Kanal und besuchen Sie den Blog unserer Website.