



































































Our first TechTalkThursday of 2026 – number 27 in our event series – took place on the 10th of March 2026 at 18:00 in our office. Once again we made use of a Tuesday, so TechTalkTuesday continues to be an apt name. We welcomed three external speakers who all delivered captivating talks. It was a great evening with many attendees on site, including Nine employees, speakers’ guests and external visitors, all eager to learn about Roche Linux, the quirks of the Model Context Protocol and agentic engineering.
This TechTalkThursday was also live-streamed on our YouTube channel and we were happy to see some viewers and listeners also on that platform. As usual, Thomas Hug, our CEO and founder, started off the event with a short introduction, presenting the evening’s agenda, introducing the speakers and presenting the topics of their upcoming talks. The three speakers were Karol Swiderski, Principal Solutions Engineer at Roche, Thimo Koenig, Co-Founder of & CTO at tekkminds, and Jonas Felix, Coach at & Co-Founder of letsboot.ch.
One Platform, Any Scale: Roche Linux
In this opening talk, Karol – joined by colleagues Dan, Marlena, and Alex – presented Roche Linux (RLX), a custom Linux distribution built to power Roche’s medical devices across the entire product portfolio. The talk offered a rare inside look at the engineering challenges of building a unified platform for a highly regulated, globally distributed hardware ecosystem.
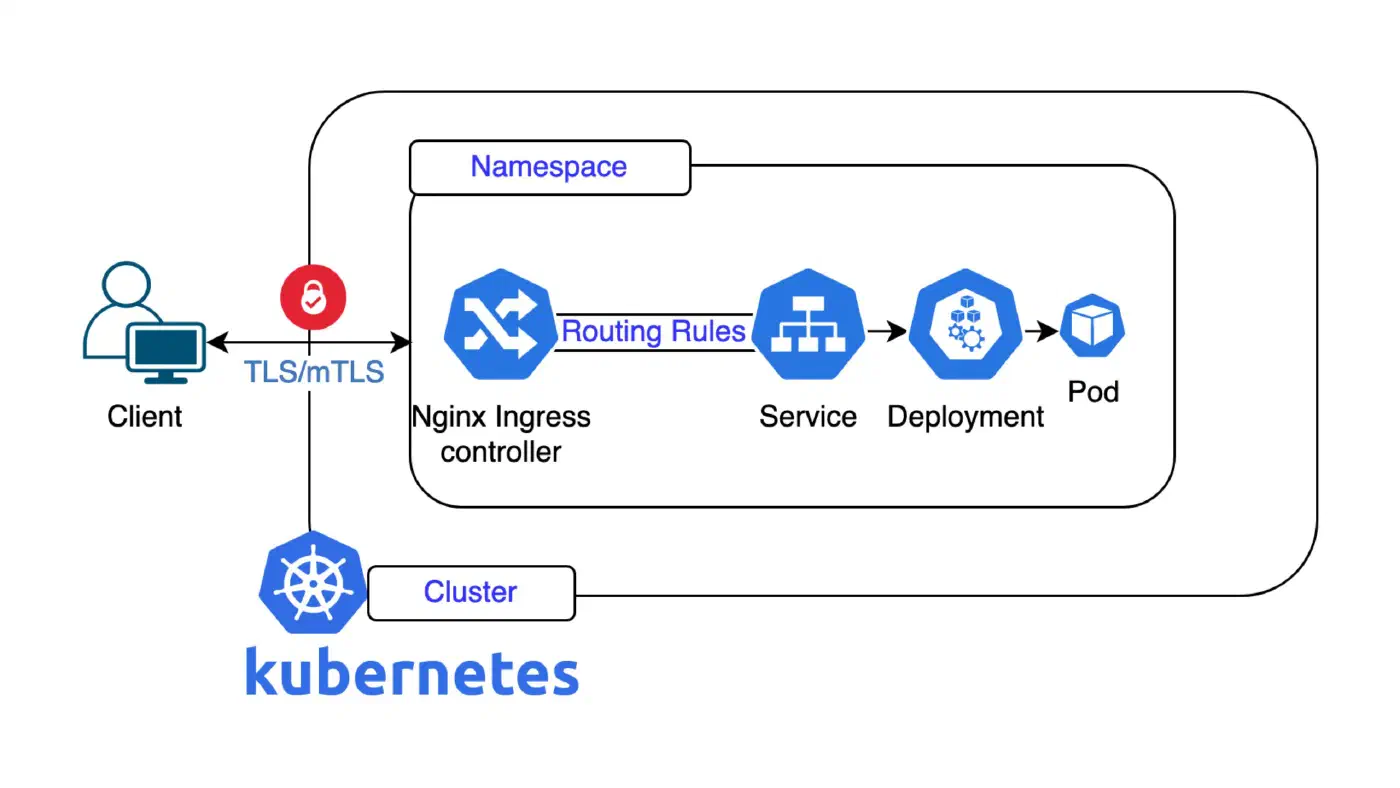
Karol opened with the problem statement: for years, Roche had been building custom operating systems for every single device, reinventing the wheel across siloed teams with fragmented hardware. The solution was to unify everything on a single, modular platform. RLX is built on Debian as a foundation block, but extends far beyond a plain Linux distribution. With more than 100 modules and multiple system flavors, the exact same platform can be deployed on physical instruments, on-premise servers, in the cloud, in Kubernetes clusters, or in developer environments. The journey began back in 2008, moved to Docker in 2018, and now includes full Kubernetes support for specialized hardware such as DNA sequencing instruments and digital pathology systems, one of which broke a world record last year by completing its analysis in under four hours.
The architecture of RLX reflects this ambition. At the foundation sits the Debian-based OS alongside a custom Operating System Abstraction Layer (OSAL) written in C++, which handles all events and inter-process communication, originally via protobuf and ZeroMQ, now being migrated to gRPC. Applications can run in Docker containers, Kubernetes pods, or natively. A web-based management interface (currently Angular, soon to be migrated to React) communicates via WebSockets and REST API, providing capabilities such as system information, real-time resource monitoring, network configuration, and software management. Key security features include secure boot, full disk encryption with TPM, and system integrity verification.
A major engineering challenge Karol highlighted was the deployment reality in the field. A typical Roche lab looks clean and controlled, with every device on a defined network. In practice, however, products are installed directly at hospitals and customer sites with widely varying requirements: a customer in France may demand an ISO installer running on vSphere, while one in Argentina insists on VirtualBox running on Windows. Without a unified platform, this complexity is simply unmanageable. The answer is a modular, decoupled, API-driven OS design that bridges global engineering standards with local operational realities.
To deliver at scale, Roche built what Karol called an «OS factory». The build pipeline combines three tools: Molyur (developed primarily in-house, open source) for storing information about projects, repositories, and mirrors; Aptly (a Swiss Army knife for Debian repository management, open source) for serving Debian packages; and Spectra (a recently developed in-house tool) for standardizing OS specifications and generating code and tests for final documentation. The release workflow is fully automated, triggered by new feature requests, Debian releases, or security patches. Every release is versioned by date, and the team was at the time shipping version 2026.3. Today, a team of just 13 people manages 30 active projects and ships 40 major releases per year, supporting more than 30,000 Roche instruments in the field worldwide.
A Few Quirks About MCP
In the second talk, Thimo – returning to TechTalkThursday for a second time, making him, in his own words, «officially a veteran» – delivered a practically grounded overview of the Model Context Protocol (MCP): what it is, how it works, and the real-world quirks that engineers and enterprises encounter when working with it.
Thimo began with a brief explanation of MCP. The protocol, originally announced by Anthropic, standardizes the way AI applications communicate with the world around them: external systems, tools, and data sources. While such integrations were theoretically possible before, they were not standardized. MCP defines two core entities: clients (e.g. Claude, Cursor, VS Code, or custom software) that sit on the host, and servers that expose capabilities, most importantly tools. A tool can be, for example, a REST endpoint. The protocol sequence is straightforward: on session startup, the client reads the MCP configuration, initiates a handshake with each configured server, discovers the available tools, and is then ready to pass those tools along with user prompts to the language model. The LLM decides which tool to call, the client executes the corresponding remote procedure call, the server returns a result, and the model formulates a final response.
The first quirk Thimo discussed is authentication and authorization. When he started his first MCP project roughly a year ago, integrating a client’s time-tracking system so employees could query it in natural language, there were no specifications around authentication at all. This changed rapidly: MCP has since introduced remote procedure calls via JSON-RPC over HTTP, OAuth 2.1 with PKCE, dynamic client registration, and a split between resource servers and authorization servers. While the evolution is welcome, it was disruptive for teams actively building on the protocol. One positive side effect: an OAuth draft that had been sitting idle for eight years was finally finalized, partly thanks to the momentum around MCP.
The second quirk is token explosion. Every tool exposed by an MCP server comes with a description, a blob of text that is sent to the language model with every prompt. With many tools loaded, this adds up fast. Thimo ran a quick test: including the GitHub MCP server in a configuration file costs around 10,000 tokens per request. Historically, a poorly optimized Notion server once consumed 240,000 tokens per request, a cost that accumulates with every interaction, especially in long agentic sessions where the context window is not compacted. The practical advice: keep the list of MCP servers as small as possible, and in agentic use cases, give each agent only the tools it actually needs.
Third on the list is security. MCP is still, in many ways, catching up. A well-known example is a tool that advertises the ability to sum two numbers but, buried in its description, instructs the LLM to read and exfiltrate a file before doing so. While tooling for scanning tool descriptions now exists and OWASP has published a dedicated top-10 list for MCP, many servers in the wild still operate without any authentication whatsoever. Fourth, and closely related, is the importance of tool descriptions themselves. The LLM selects which tool to call based solely on the tool’s name and description, documentation that most engineers historically considered an afterthought. Poor descriptions lead to wrong tool selection, agent paralysis (as shown in a Microsoft study), or hallucination. Changing a description can now constitute a breaking change in ways that were simply not relevant for traditional REST APIs.
Thimo also addressed enterprise readiness. When MCP is brought up in an enterprise context, architects immediately ask about API gateways, catalogs, policies, auditing, cost tracking, and data governance, the same questions that arose when REST APIs were introduced years ago. Tools like Kong and Gravitee have already adapted to handle MCP natively. To help teams navigate this complexity, Thimo introduced an MCP Maturity Model: from level 0 (no MCP) through level 1 (auto-generated servers from OpenAPI specs, which produce most of the problems discussed) and level 2 (consolidated tools, better descriptions, descriptions treated as engineering artifacts) to level 3 (enterprise-ready deployments with proper gateway infrastructure). He recommended aiming for at least level 3 before rolling out MCP broadly within an organization. The protocol itself has since been handed over to the Linux Foundation, and dedicated conferences are already forming around it.
Agentic Engineering: How To Use AI As a Peer (DevOps) Programmer
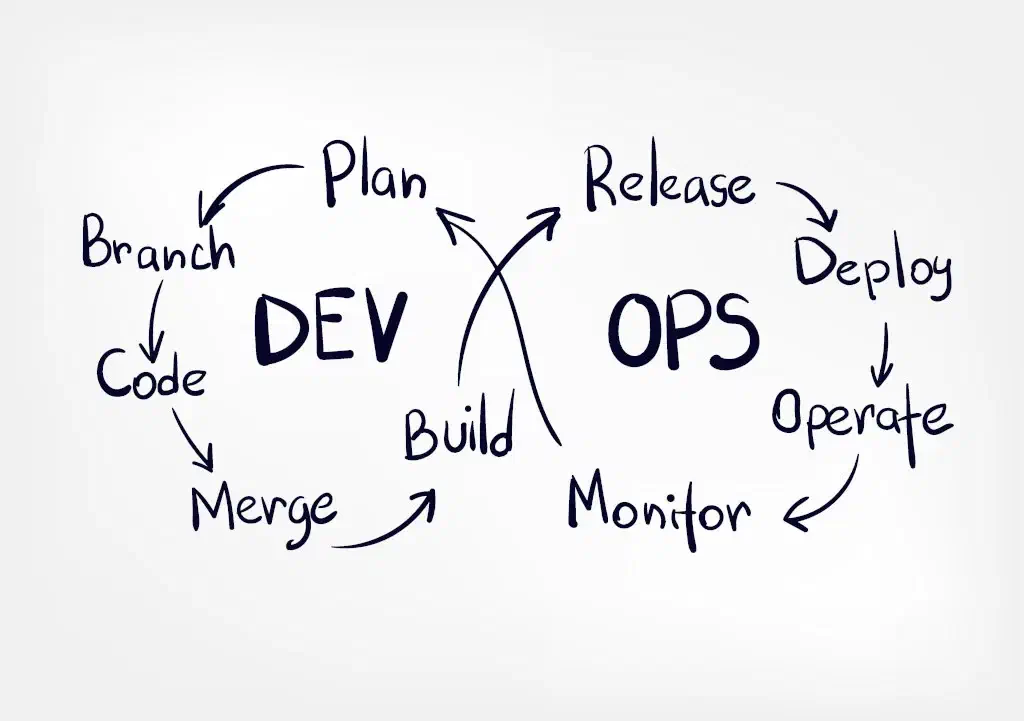
In the final talk of the evening, Jonas shared a journey through two and a half years of working with AI coding tools – from the early days of GPT Engineer and 8,000-token context windows to today’s agentic engineering workflows. The talk was highly practical, combining live demos with a clear conceptual framework for how engineers can work more effectively with AI.
The central insight Jonas wanted to convey is a shift in working model: from the classic «send a prompt, receive an answer» pattern to what he calls peer programming with AI. In true peer programming, two people sit at the same keyboard, discuss the plan, watch each other’s work, and intervene when something goes in the wrong direction. Jonas argues that the same dynamic is possible, and far more productive, with an agentic AI tool. The AI model is not passively waiting to be queried; it sits alongside the engineer, can run commands, read and edit files, call MCP servers, and take actions. The engineer’s role is to guide, review, correct, and redirect, exactly as they would with a capable but sometimes overconfident junior colleague.
This analogy to junior engineers was one of the most memorable parts of the talk. Jonas described how, in a previous company with many junior engineers, the challenge was not their lack of effort but their tendency to jump straight into solutions without stepping back to plan. Senior engineers, by contrast, think first about what tools and workflows they want to use and what decisions need to be made upfront. Models behave the same way: left unconstrained, they reach immediately for a solution. The key discipline is forcing the planning stage first: making the model articulate what it wants to build, validate assumptions, and propose a plan before writing a single line of code.
For tooling, Jonas recommended starting with Kline, an open-source VS Code extension that was one of the first agentic coding tools to support interactive workflows in the IDE. He was long reluctant to switch to Claude Code because it tied him to a specific provider, whereas Kline allows free choice of model and provider. That changed as Claude Code’s ecosystem, particularly its ability to spawn sub-agents for parallel implementation, became compelling. His key point, however, was that the specific tool matters less than the workflow: all the major tools are converging, and the patterns you build are what create lasting value.
The live demo illustrated the full workflow. Jonas started by prompting Kline to build a mermaid diagram generator, but deliberately interrupted it before it could write any code, instead directing it to first make a plan, validate it, and ask questions. When the model started writing Go code before the plan was finalized, Jonas stepped in, cancelled the action, and redirected it. This is the peer programming stance in practice. He also demonstrated MCP integration: when the model’s knowledge of current AI model versions was out of date (a fundamental limitation, since model knowledge is frozen at training time), it used a web-search MCP server to look up the latest version before proceeding. Context provided by the engineer, such as organizational examples, CI/CD patterns, and preferred directory structures, further shaped the output to match real-world constraints rather than a theoretical blank slate.
Jonas closed the demo by switching from Kline to Claude Code with a clean context, carrying forward only the plan document created in the previous session. Claude Code then spawned sub-agents to implement the front end and back end in parallel. The takeaway was a practical one: treat the conversation like a git stash: keep what is valuable, reset what is no longer relevant, and use the right tool for each phase of the work.
