



































































There are days when the red light goes on for system engineers. April 30, 2026 was one of them.
At 8:29, an article regarding a 0-day exploit in the Linux kernel, publicly disclosed on cybersecuritynews.com, was shared in our internal Slack. CVE-2026-31431, nicknamed “Copy Fail”. A local privilege escalation in the Linux kernel, introduced in kernel version 4.14 in 2017. And – the cherry on top – a working exploit is already available on GitHub. A handful of lines of Python, and any unprivileged user is able to become root:
www-data@test-noble03:~ $ python3 copy_fail_exp.py
# id
uid=0(root) gid=33(www-data) groups=33(www-data),4(adm),112(ssl-cert)
That simple. That fast. On a recent Ubuntu Noble (24.04). And no updated kernel was available yet for our Ubuntu fleet at that point.
Why This Is a Problem
On a typical web server, the application runs as an unprivileged user, usually www-data. That is defense in depth: even if an attacker manages to exploit a vulnerability in PHP, Node, or Ruby, they only get the rights of that one user. Unix file permissions then keep them out of other customers’ data and away from root-owned secrets – provided those permissions are set correctly. The blast radius stays bounded.
A local privilege escalation bridges that layer. “Compromised web app” turns into “compromised server”. While the kernel is the last line of defense, and application security is the first, we need to take precautions and secure that last line of defense with the tools available to us, especially when a working exploit is already public and trivial to run.
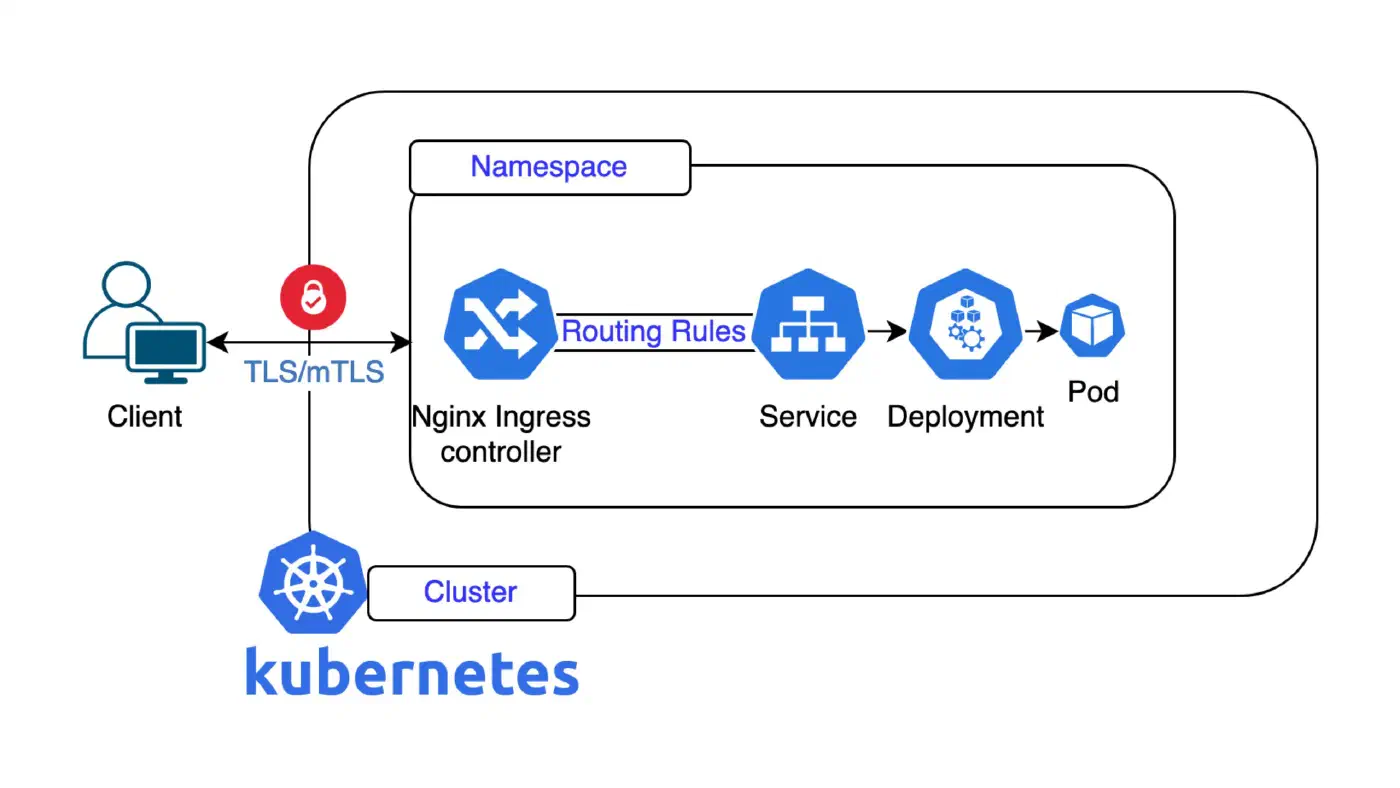
The team also quickly verified that the exploit works not only on virtual machines or dedicated servers, but also inside a container environment. Which means that our Kubernetes worker nodes might be exposed as well. A kernel bug that hands root to an unprivileged process undermines the isolation of a shared platform like Deploio: exactly the scenario you want to avoid at all costs.
Mitigation Instead of Waiting
Issues of that magnitude require instant attention and action. With no patch available yet, a mitigation needed to be implemented as soon as possible. The vulnerability is an out-of-bounds write in the kernel module algif_aead, only reachable through the AF_ALG socket interface of the Crypto User API. Unload the module and prevent it from being loaded again, and the attack vector is mitigated.
echo "install algif_aead /bin/false" > /etc/modprobe.d/disable-algif-aead.conf
rmmod algif_aead 2>/dev/null
The mitigation was shared in our internal communication, tested first, then integrated into our automation and rolled out to all our Managed Servers. After the rollout, we verified the mitigation again on multiple machines, ensuring it was working as intended. We were no longer able to reproduce the privilege escalation.
From the first Slack message to a confirmed-safe state across the fleet in just about an hour.
And Kubernetes?
Our Kubernetes platform NKE and Deploio do not run on Ubuntu, but on Flatcar Container Linux. One engineer took a look at the kernel configuration of the versions we run, on staging and production. The result: CONFIG_CRYPTO_USER_API_AEAD is disabled, and algif_aead is not even shipped as a module. Only algif_hash and algif_skcipher are present.
In simple words: the attack vector via the kernel module algif_aead simply does not exist on our Kubernetes and Deploio environments. Flatcar’s maintainers had disabled CONFIG_CRYPTO_USER_API_AEAD for their own reasons, and we happened to benefit. Flatcar themselves confirmed they are not affected by this CVE.
We will of course keep an eye on the Flatcar release notes in case anything changes. But this morning, we got to exhale on that front.
What I’m Taking Away From Today
Mitigations buy time. When no patch is available yet, surgically removing the attack vector – here, unloading algif_aead and blocking it from being reloaded – can bridge the gap until the upstream patch lands. It’s not a substitute for patching, but it’s the difference between “exposed for hours” and “exposed for days”.
A great team is everything. Around half a dozen engineers were active in the Slack thread and the discussion was a textbook example: someone finds the problem, someone verifies the exploit, someone researches the mitigation, someone rolls it out, someone audits the fleet, someone tests that it actually works. No escalation and no drama, only well orchestrated engineering. Hats off to everyone involved.
If you run a Root Server with us, you’re at the wheel yourself: that’s the deal. If that’s you: the mitigation above (install algif_aead /bin/false plus rmmod) takes about a minute to apply, no reboot required. As soon as your distribution ships the kernel patch, just update and reboot.
If you’ve ever wondered what the word “Managed” in Managed Server actually means in practice: this was a perfectly normal Thursday morning.
