





















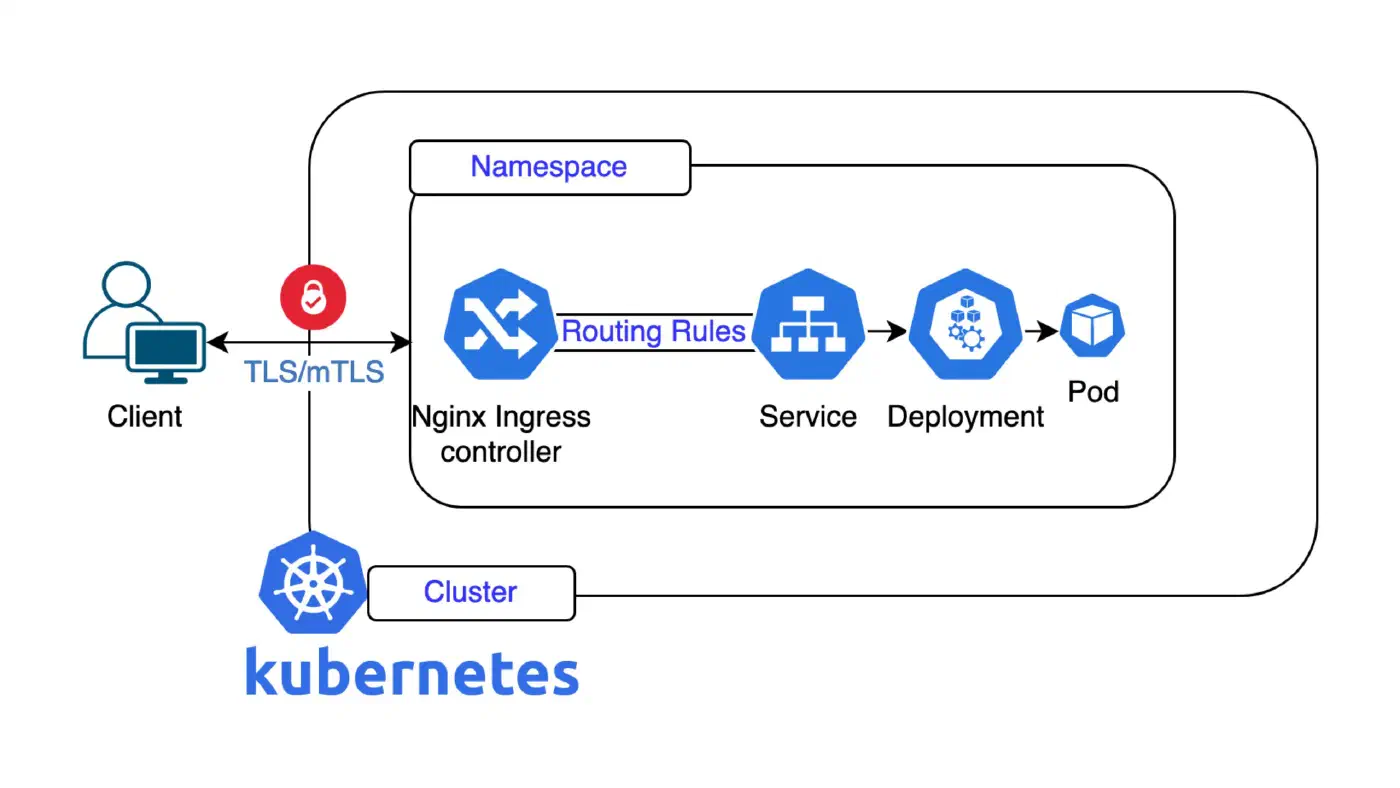














































Kubernetes has become the de-facto standard for containerised workloads. According to the CNCF Annual Survey 2025, 82% of container users now run Kubernetes in production. Most teams starting out invest time and energy into cluster setup, writing their first Helm Charts, and deploying initial applications. It works and the cluster runs.
What comes next is routinely underestimated.
Day-1 vs. Day-2: The Real Work Begins After Launch
The term “Day-2 Operations” describes everything that happens after a platform is initially set up: ongoing maintenance, upgrades, security patches, monitoring, alerting, backup, and disaster recovery. In the Kubernetes world, this burden is substantial and grows with the number of workloads.
Four concrete examples from everyday operations:
Cluster upgrades: Kubernetes releases three minor versions per year. Each version receives security patches for a maximum of 14 months under the N-2 policy. An upgrade is not a simple version bump: minor releases cannot be skipped. Going from 1.34 directly to 1.36 is not supported; the path always leads through 1.35. The correct sequence: control plane first (API server, etcd, scheduler, controller manager), then worker nodes. Each node is individually cordoned (no new pod scheduling), drained (running pods are safely rescheduled to other nodes), upgraded (kubelet, kube-proxy), and then uncordoned. Add-ons also need to be brought to compatible versions in parallel: CNI plugin, CoreDNS, CSI driver. Each minor version jump can also invalidate existing manifests, as API groups and versions are periodically deprecated and removed. Teams that don’t address this early risk rollout failures in production during their next upgrade.
Observability: A Kubernetes cluster without monitoring is flying blind. Without metrics, there is no baseline for SLA tracking, no foundation for alerting, and no way to debug latency issues. A production-grade setup with Prometheus, Grafana, Loki, and Alertmanager requires initial expertise and ongoing maintenance: tuning dashboards, refining alert rules, configuring log retention, and preventing cardinality explosions in the Prometheus TSDB. Skip this and you find out about problems only after they have already affected end users.
Secret management: Kubernetes Secrets are not encrypted by default. They are stored in etcd as Base64-encoded values. Base64 is encoding, not encryption: anyone with read access to etcd or the appropriate RBAC permissions can read all secrets in plain text. A production-grade setup requires either Encryption at Rest (via EncryptionConfiguration for etcd) or an external secret store. The External Secrets Operator reads secrets from external stores like HashiCorp Vault or AWS Secrets Manager and injects them as native Kubernetes Secrets at runtime. This significantly reduces the attack surface but requires dedicated expertise and ongoing maintenance.
Network policies and RBAC: In a freshly set up Kubernetes cluster, every pod can communicate with every other pod by default, regardless of namespace or team. Useful in a development environment, but a security risk in production. Granular NetworkPolicy resources need to be explicitly defined to restrict ingress and egress traffic between workloads. RBAC adds another dimension: who is allowed to read, create, or delete which Kubernetes resources? Overly broad assignment of the ClusterAdmin role is one of the most common security mistakes in self-managed clusters. Both network policies and RBAC require a well-thought-out initial design and ongoing review, especially as teams grow.
How closely network isolation, secret management, and security patching are connected was made strikingly clear by IngressNightmare in March 2025: CVE-2025-1974 (CVSS 9.8) allowed unauthenticated remote code execution (RCE) via the ingress controller’s admission webhook, enabling full cluster takeover, including read access to all Secrets across all namespaces. Over 40% of production Kubernetes environments worldwide were affected. Fix: ingress-nginx v1.12.1 or v1.11.5+. The incident illustrates: falling behind on security patches puts exactly the data at risk that the secret store was supposed to protect.
Update (March 2026): ingress-nginx was officially retired, so no further releases, security patches, or bug fixes will be issued. Teams still running ingress-nginx should migrate urgently. HAProxy (HAProxy Technologies’ Kubernetes Ingress Controller) is a well-supported alternative with active development including Gateway API support. According to HAProxy Technologies’ own benchmarks, it achieves higher throughput and lower latency than ingress-nginx.
What This Means for Your Team
Every hour your team spends on Kubernetes platform operations is one hour less for product development. The CNCF Annual Survey 2024 consistently identifies a lack of training and internal expertise as a leading Kubernetes challenge across organisations. For small and medium-sized teams without dedicated platform engineering, this is a serious resource question. CKA-certified engineers are expensive and hard to find on the Swiss market.
The alternative: outsource the platform ops burden rather than building it in-house.
What a Managed Kubernetes Service Actually Covers
Not all managed Kubernetes offerings are equal. The difference lies in what is actually managed. Many providers only handle the control plane, the rest stays with the customer.
With Nine Kubernetes Engine (NKE), we provide the complete stack:
- RKE2-based (CIS-hardened, FIPS-capable) with Cilium as CNI (CNCF Graduated Project)
- Automated cluster upgrades (control plane and worker nodes, including correct upgrade sequencing without version skipping)
- Full observability stack: Prometheus, Grafana, Loki, Alertmanager (preconfigured and production-ready from day one)
- GitOps with ArgoCD
- Secret management via External Secrets Operator
- HAProxy Kubernetes Ingress Controller (high-throughput, actively maintained, Gateway API support)
- cert-manager for automated TLS certificates
- Private container registry
- Automated backup and restore with configurable schedules
- Node autoscaling via KEDA (CNCF Graduated Project, event-driven, scales to zero)
- 99.5% uptime SLA on Nine infrastructure (99.95% on Managed GKE)
Behind all of this are CKA-certified engineers as direct contacts and no L1 support or anonymous ticket system.
«Thanks to working with Nine, we can focus on what we do best: developing software solutions for the healthcare sector. The infrastructure runs securely and reliably in the background, so we can offer our customers the best solutions. With Nine, we have a strong, local, and reliable partner at our side.»
Moritz Habegger, healthinal
For Regulated Industries: Swiss Data Sovereignty Included
NKE runs on Swiss infrastructure. All data remains in Switzerland, with no CLOUD Act or FISA exposure. We are ISO 27001-certified since 2013 and ISO 9001-certified; NKE is GDPR and nDSG compliant. This matters for companies in regulated industries such as healthcare, fintech, or the public sector, but also for anyone who wants to avoid US jurisdiction over their data.
For teams that need global scale, we also offer Managed GKE (Google Kubernetes Engine, Zurich region), with the same operational model.
Conclusion
Operating Kubernetes is not a one-time investment. Day-2 operations are ongoing work and they grow with the cluster. The question is not whether this effort exists, but who carries it: your team or a specialist partner.
If you’d like to know what to consider before getting started with Kubernetes, we’ve put together a practical checklist for engineering teams:
👉 Download Kubernetes checklist
Still evaluating whether Kubernetes is the right move? In our free one-hour webinar, we walk through how Kubernetes works in practice – with a live demo and Q&A:
👉 Register for the free webinar
Or speak directly to our experts, without any commitment:
