



































































Unser erster TechTalkThursday im Jahr 2026 – die 27. Veranstaltung unserer Eventreihe – fand am 10. März 2026 um 18 Uhr in unserem Büro statt. Wieder einmal nutzten wir einen Dienstag dafür, weshalb TechTalkTuesday weiterhin eine passende Bezeichnung wäre. Wir durften drei externe Referenten begrüssen, die alle spannende Vorträge hielten. Es war ein toller Abend mit vielen Anwesenden vor Ort, darunter Nine-Mitarbeitende, Gäste der Referenten und externe Teilnehmende, alle neugierig auf Roche Linux, die Tücken des Model Context Protocol und Agentic Engineering.
Dieser TechTalkThursday wurde auch live auf unserem YouTube-Kanal übertragen, und wir haben uns gefreut, dass auch einige Zuschauende auf dieser Plattform dabei waren. Wie üblich eröffnete Thomas Hug, unser CEO und Gründer, die Veranstaltung mit einer kurzen Einführung, in der er die Agenda des Abends vorstellte, die Referenten ankündigte und die Themen ihrer Vorträge präsentierte. Die drei Referenten waren Karol Swiderski, Principal Solutions Engineer bei Roche, Thimo Koenig, Co-Founder von & CTO bei tekkminds, und Jonas Felix, Coach bei & Co-Founder von letsboot.ch.
One Platform, Any Scale: Roche Linux
In diesem Eröffnungsvortrag präsentierte Karol – begleitet von seinen Kollegen Dan, Marlena und Alex – Roche Linux (RLX), eine massgeschneiderte Linux-Distribution, die Roches Medizinprodukte über das gesamte Produktportfolio hinweg antreibt. Der Vortrag bot einen seltenen Einblick in die Herausforderungen beim Aufbau einer einheitlichen Plattform für ein hochreguliertes, weltweit verteiltes Hardware-Ökosystem.
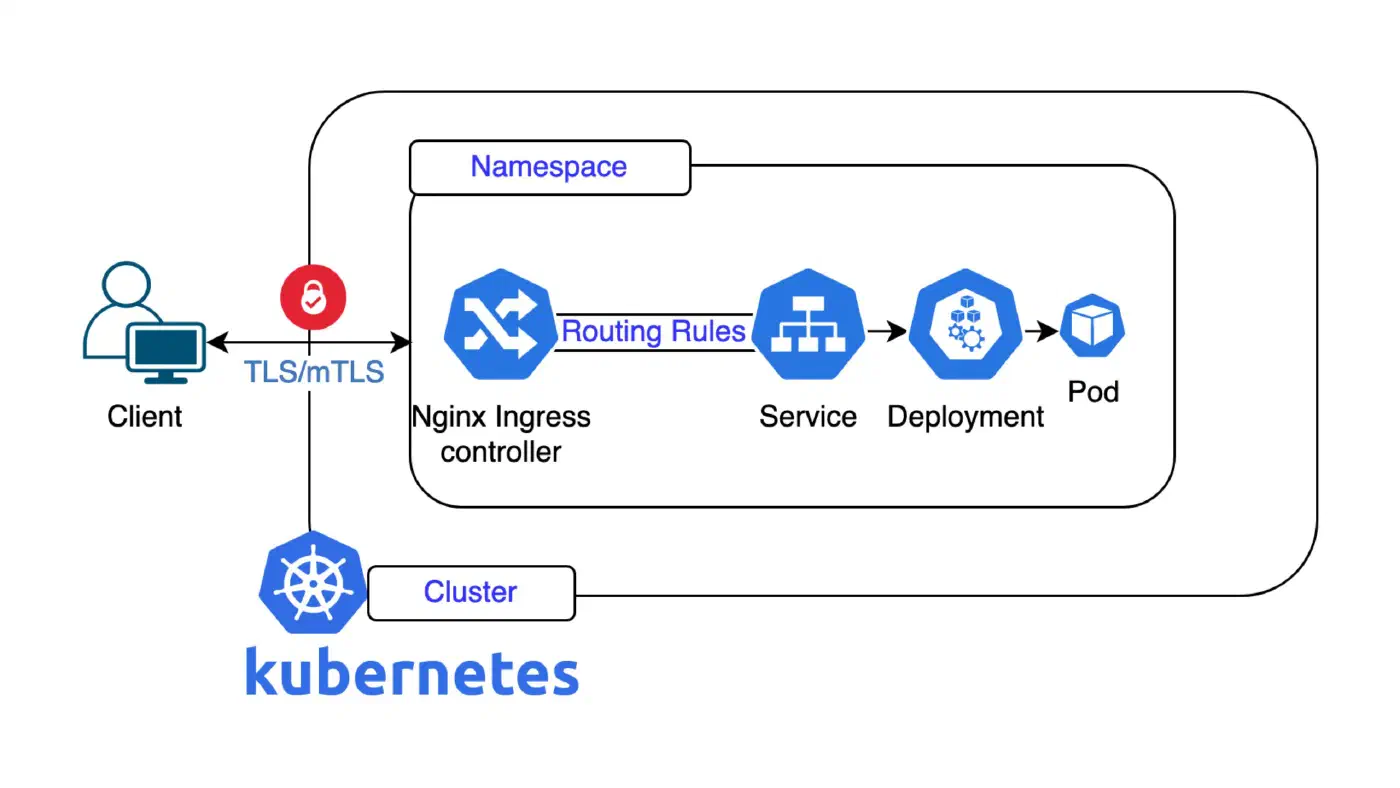
Karol begann mit der Problemstellung: Jahrelang hatte Roche für jedes einzelne Gerät eigene Betriebssysteme gebaut, immer wieder das Rad neu erfunden, mit isolierten Teams und fragmentierter Hardware. Die Lösung war, alles auf einer einzigen, modularen Plattform zu vereinen. RLX basiert auf Debian als Fundament, geht aber weit über eine gewöhnliche Linux-Distribution hinaus. Mit mehr als 100 Modulen und mehreren System-Flavours lässt sich exakt dieselbe Plattform auf physischen Instrumenten, On-Premise-Servern, in der Cloud, in Kubernetes-Clustern oder in Entwicklungsumgebungen einsetzen. Die Reise begann 2008, 2018 kam Docker dazu, und heute umfasst die Plattform volle Kubernetes-Unterstützung für Spezial-Hardware wie DNA-Sequenzierungsinstrumente und digitale Pathologiesysteme, wobei eines davon letztes Jahr einen Weltrekord aufstellte, indem es seine Analyse in unter vier Stunden abschloss.
Die Architektur von RLX spiegelt diesen Anspruch wider. Als Fundament dient das Debian-basierte Betriebssystem zusammen mit einem in C++ geschriebenen Operating System Abstraction Layer (OSAL), der alle Ereignisse und die Interprozesskommunikation verwaltet, ursprünglich via protobuf und ZeroMQ, jetzt im Übergang zu gRPC. Anwendungen können in Docker-Containern, Kubernetes-Pods oder nativ betrieben werden. Eine webbasierte Verwaltungsoberfläche (aktuell Angular, bald React) kommuniziert via WebSockets und REST API und bietet Funktionen wie Systeminformationen, Echtzeit-Ressourcenmonitoring, Netzwerkkonfiguration und Software-Management. Zu den zentralen Sicherheitsmerkmalen gehören Secure Boot, vollständige Festplattenverschlüsselung mit TPM und Systemintegritätsprüfung.
Eine wesentliche technische Herausforderung, die Karol hervorhob, ist die Deploymentrealität im Feld. Ein typisches Roche-Labor wirkt sauber und kontrolliert, mit jedem Gerät in einem definierten Netzwerk. In der Praxis werden Produkte jedoch direkt bei Spitälern und Kundenstandorten mit sehr unterschiedlichen Anforderungen installiert: Ein Kunde in Frankreich verlangt möglicherweise einen ISO-Installer für vSphere, während ein Kunde in Argentinien auf VirtualBox unter Windows besteht. Ohne eine einheitliche Plattform ist diese Komplexität schlicht nicht handhabbar. Die Antwort ist ein modulares, entkoppeltes, API-getriebenes Betriebssystemdesign, das globale Engineering-Standards mit lokalen Betriebsrealitäten verbindet.
Um in diesem Massstab ausliefern zu können, hat Roche eine sogenannte «OS-Fabrik» aufgebaut. Die Build-Pipeline kombiniert drei Tools: Molyur (hauptsächlich intern entwickelt, Open Source) zur Verwaltung von Projektinformationen, Repositories und Mirrors; Aptly (ein Schweizer Taschenmesser für Debian-Repository-Management, Open Source) für die Bereitstellung von Debian-Paketen; und Spectra (ein kürzlich intern entwickeltes Tool) zur Standardisierung von OS-Spezifikationen sowie zur Codegenerierung und Testunterstützung für die finale Dokumentation. Der Release-Workflow ist vollständig automatisiert und wird durch neue Feature-Requests, Debian-Releases oder Sicherheits-Patches ausgelöst. Jedes Release wird nach Datum versioniert, und das Team lieferte zum Zeitpunkt des Vortrags Version 2026.3 aus. Heute verwaltet ein Team von gerade einmal 13 Personen 30 aktive Projekte und liefert 40 Major-Releases pro Jahr und unterstützt dabei mehr als 30'000 Roche-Instrumente weltweit im Einsatz.
A Few Quirks About MCP
Im zweiten Vortrag – Thimo war bereits zum zweiten Mal beim TechTalkThursday zu Gast und bezeichnete sich selbst damit als «offiziellen Veteran» – lieferte er einen praxisnahen Überblick über das Model Context Protocol (MCP): was es ist, wie es funktioniert und welche Tücken Entwickler und Unternehmen im echten Einsatz damit erleben.
Thimo begann mit einer kurzen Erklärung von MCP. Das ursprünglich von Anthropic angekündigte Protokoll standardisiert, wie KI-Anwendungen mit ihrer Umgebung kommunizieren: also mit externen Systemen, Tools und Datenquellen. Solche Integrationen waren zwar theoretisch schon vorher möglich, aber nicht standardisiert. MCP definiert zwei Kernentitäten: Clients (z.B. Claude, Cursor, VS Code oder eigene Software), die auf dem Host laufen, und Server, die Fähigkeiten bereitstellen, allem voran Tools. Ein Tool kann beispielsweise ein REST-Endpoint sein. Der Protokollablauf ist geradlinig: Beim Start liest der Client die MCP-Konfiguration, initiiert einen Handshake mit jedem konfigurierten Server, entdeckt die verfügbaren Tools und ist dann bereit, diese Tools zusammen mit Benutzer-Prompts an das Sprachmodell zu übergeben. Das LLM entscheidet, welches Tool aufgerufen werden soll, der Client führt den entsprechenden Remote-Procedure-Call durch, der Server gibt ein Ergebnis zurück, und das Modell formuliert eine abschliessende Antwort.
Die erste Tücke, die Thimo besprach, ist Authentifizierung und Autorisierung. Als er sein erstes MCP-Projekt startete, die Integration eines Zeiterfassungssystems eines Kunden, damit Mitarbeitende via Chat damit interagieren konnten, gab es keinerlei Spezifikationen rund um Authentifizierung. Das änderte sich rasch: MCP hat seither Remote-Procedure-Calls via JSON-RPC über HTTP eingeführt, OAuth 2.1 mit PKCE, dynamische Client-Registrierung und eine Trennung von Resource Server und Authorization Server. Die Entwicklung ist willkommen, war für Teams, die aktiv darauf aufbauten, jedoch disruptiv. Ein positiver Nebeneffekt: Ein OAuth-Draft, der acht Jahre lang unbearbeitet herumlag, wurde dank des MCP-Momentums endlich finalisiert.
Die zweite Tücke ist die sogenannte Token-Explosion. Jedes Tool, das ein MCP-Server bereitstellt, hat eine Beschreibung, einen Textblock, der mit jedem Prompt an das Sprachmodell gesendet wird. Bei vielen Tools addiert sich das schnell. Thimo machte einen kurzen Test: Der GitHub-MCP-Server allein kostet rund 10'000 Tokens pro Anfrage. Ein schlecht optimierter Notion-Server verbrauchte früher gar 240'000 Tokens pro Anfrage - Kosten, die sich bei jeder Interaktion summieren, insbesondere in langen agentischen Sessions, in denen das Kontextfenster nicht kompaktiert wird. Der praktische Rat: Die Liste der MCP-Server so klein wie möglich halten und agentischen Einheiten nur die Tools geben, die sie wirklich benötigen.
Drittens steht das Thema Sicherheit. MCP befindet sich in vielerlei Hinsicht noch im Aufholmodus. Ein bekanntes Beispiel ist ein Tool, das vorgibt, zwei Zahlen zu addieren, in seiner Beschreibung aber versteckt das LLM anweist, zuerst eine Datei zu lesen und zu exfiltrieren. Während mittlerweile Tooling zum Scannen von Tool-Beschreibungen existiert und OWASP eine eigene Top-10-Liste für MCP veröffentlicht hat, laufen viele Server im freien Internet noch immer ohne jegliche Authentifizierung. Viertens, und eng damit verknüpft, ist die Qualität von Tool-Beschreibungen entscheidend. Das LLM wählt das aufzurufende Tool ausschliesslich anhand seines Namens und seiner Beschreibung, also anhand von Dokumentation, die Entwickler früher als Nebensache behandelten. Schlechte Beschreibungen führen zu falscher Tool-Auswahl, Agenten-Lähmung (wie eine Microsoft-Studie zeigt) oder Halluzinationen. Eine Beschreibung zu ändern kann heute zu einem Breaking Change werden, auf eine Art, die bei klassischen REST-APIs schlicht keine Rolle spielte.
Thimo sprach auch die Enterprise-Tauglichkeit an. Wenn MCP in einem Unternehmenskontext eingebracht wird, fragen Architekten sofort nach API-Gateways, Katalogen, Richtlinien, Auditing, Kosten-Tracking und Data Governance, dieselben Fragen, die bei der Einführung von REST-APIs vor Jahren gestellt wurden. Tools wie Kong und Gravitee haben sich bereits angepasst, um MCP nativ zu unterstützen. Um Teams durch diese Komplexität zu führen, stellte Thimo ein MCP-Reifegradmodell vor: von Level 0 (kein MCP) über Level 1 (automatisch generierte Server aus OpenAPI-Spezifikationen, die die meisten der besprochenen Probleme erzeugen) und Level 2 (konsolidierte Tools, bessere Beschreibungen, die als Engineering-Artefakte behandelt werden) bis Level 3 (enterprise-taugliche Deployments mit geeigneter Gateway-Infrastruktur). Er empfahl, mindestens Level 3 anzustreben, bevor MCP unternehmensweit ausgerollt wird. Das Protokoll selbst wurde inzwischen an die Linux Foundation übergeben, und dedizierte Konferenzen bilden sich bereits darum.
Agentic Engineering: How To Use AI As a Peer (DevOps) Programmer
Im letzten Vortrag des Abends teilte Jonas eine zweieinhalb Jahre lange Reise mit KI-Coding-Tools – von den Anfängen mit GPT Engineer und 8'000-Token-Kontextfenstern bis zu den heutigen agentischen Engineering-Workflows. Der Vortrag war äusserst praxisorientiert und kombinierte Live-Demos mit einem klaren konzeptionellen Rahmen, wie Entwicklerinnen und Entwickler effektiver mit KI zusammenarbeiten können.
Die zentrale Erkenntnis, die Jonas vermitteln wollte, ist ein Wandel im Arbeitsmodell: weg vom klassischen «Prompt senden, Antwort empfangen» hin zu dem, was er Peer-Programming mit KI nennt. Beim echten Pair-Programming sitzen zwei Personen am gleichen Keyboard, besprechen den Plan, beobachten die Arbeit der jeweils anderen Person und greifen ein, wenn etwas in die falsche Richtung läuft. Jonas argumentiert, dass dieselbe Dynamik, und deutlich produktiver, auch mit einem agentischen KI-Tool möglich ist. Das KI-Modell wartet nicht passiv auf eine Anfrage; es sitzt neben dem Entwickler, kann Befehle ausführen, Dateien lesen und bearbeiten, MCP-Server aufrufen und Aktionen durchführen. Die Rolle der Entwicklerin oder des Entwicklers ist es, zu führen, zu reviewen, zu korrigieren und umzuleiten, genau wie bei einem fähigen, aber manchmal übereifrigen Junior-Kollegen.
Diese Analogie zu Junior-Entwicklern war einer der einprägsamsten Teile des Vortrags. Jonas beschrieb, wie er in einem früheren Unternehmen mit vielen Junior-Entwicklern feststellte, dass deren Problem nicht mangelnder Einsatz war, sondern die Tendenz, sofort in Lösungen zu springen, ohne innezuhalten und zu planen. Senior-Entwickler hingegen denken zuerst darüber nach, welche Tools und Workflows sie nutzen wollen und welche Entscheidungen im Vorfeld getroffen werden müssen. Modelle verhalten sich genauso: Unkontrolliert greifen sie unmittelbar nach einer Lösung. Die entscheidende Disziplin ist es, zuerst die Planungsphase zu erzwingen: das Modell dazu zu bringen, zu artikulieren, was es bauen möchte, Annahmen zu validieren und einen Plan vorzuschlagen, bevor eine einzige Zeile Code geschrieben wird.
Als Tooling empfahl Jonas, mit Kline zu starten, einer Open-Source-VS-Code-Extension, die eine der ersten agentischen Coding-Tools war, die interaktive Workflows in der IDE unterstützte. Er zögerte lange, zu Claude Code zu wechseln, weil es ihn an einen bestimmten Anbieter gebunden hätte, während Kline die freie Wahl von Modell und Provider erlaubt. Das änderte sich, als das Ökosystem von Claude Code, insbesondere die Möglichkeit, Sub-Agents für parallele Implementierung zu spawnen, überzeugend wurde. Sein Kernpunkt war jedoch, dass das konkrete Tool weniger wichtig ist als der Workflow: Alle grossen Tools konvergieren, und die Muster, die man aufbaut, schaffen den dauerhaften Wert.
Die Live-Demo illustrierte den vollständigen Workflow. Jonas begann damit, Kline aufzufordern, einen Mermaid-Diagram-Generator zu bauen, unterbrach es aber absichtlich, bevor es Code schreiben konnte, und wies es stattdessen an, zuerst einen Plan zu erstellen, diesen zu validieren und Fragen zu stellen. Als das Modell anfing, Go-Code zu schreiben, bevor der Plan abgeschlossen war, griff Jonas ein, brach die Aktion ab und korrigierte den Kurs. Das ist die Peer-Programming-Haltung in der Praxis. Er demonstrierte auch MCP-Integration: Als das Wissen des Modells über aktuelle KI-Modellversionen veraltet war, eine grundlegende Einschränkung, da das Modell-Wissen zum Trainingszeitpunkt eingefroren ist, nutzte es einen Web-Such-MCP-Server, um die neueste Version nachzuschlagen, bevor es fortfuhr. Kontext vom Entwickler, etwa Organisationsbeispiele, CI/CD-Muster und bevorzugte Verzeichnisstrukturen, prägte die Ausgabe weiter, um echten Unternehmensanforderungen statt einem theoretischen leeren Blatt gerecht zu werden.
Jonas schloss die Demo ab, indem er von Kline zu Claude Code mit einem neuen Kontext wechselte und nur das zuvor erstellte Plandokument mitnahm. Claude Code spawnte dann Sub-Agents, um Frontend und Backend parallel zu implementieren. Das Fazit war ein praktisches: Die Konversation wie ein Git-Stash behandeln: das Wertvolle behalten, das Irrelevante verwerfen und das richtige Tool für jede Phase der Arbeit nutzen.
