



































































Kubernetes ist heute der De-facto-Standard für containerisierte Workloads. Laut CNCF Annual Survey 2025 setzen bereits 82 % der Container-Nutzerinnen und -Nutzer Kubernetes in der Produktion ein. Die meisten Teams, die damit anfangen, investieren Zeit und Energie in das Aufsetzen des Clusters, das Schreiben erster Helm Charts und das Deployen der ersten Applikationen. Das funktioniert und der Cluster läuft.
Was danach kommt, wird regelmässig unterschätzt.
Day-1 vs. Day-2: Der eigentliche Aufwand beginnt nach dem Launch
Der Begriff «Day-2 Operations» beschreibt alles, was nach dem initialen Aufsetzen einer Plattform anfällt: laufende Wartung, Upgrades, Security-Patches, Monitoring, Alerting, Backup und Disaster Recovery. In der Kubernetes-Welt ist dieser Aufwand beträchtlich und er wächst mit der Anzahl der Workloads.
Vier konkrete Beispiele aus dem Alltag:
Cluster-Upgrades: Kubernetes veröffentlicht drei Minor Releases pro Jahr. Jede Version wird unter der N-2 Policy maximal 14 Monate mit Security-Patches versorgt. Ein Upgrade ist kein simpler Versions-Bump: Minor Releases dürfen nicht übersprungen werden. Von 1.34 direkt auf 1.36 zu gehen ist nicht unterstützt; der Weg führt immer über 1.35. Die korrekte Reihenfolge: zuerst die Control Plane (API Server, etcd, Scheduler, Controller Manager), dann die Worker Nodes. Jeder Node wird einzeln cordoniert (keine neuen Pod-Schedulings), drainiert (laufende Pods werden sicher auf andere Nodes umverteilt), upgraded (kubelet, kube-proxy) und danach wieder uncordoned. Parallel dazu müssen Add-ons auf kompatible Versionen gebracht werden: CNI-Plugin, CoreDNS, CSI-Driver. Wichtig: jeder Minor-Versionssprung kann bestehende Manifeste ungültig machen. API-Gruppen und Versionen werden periodisch deprecated und entfernt. Wer das nicht frühzeitig adressiert, riskiert beim Upgrade einen Rollout-Fehler in Produktion.
Observability: Ein Kubernetes-Cluster ohne Monitoring ist ein Blindflug. Ohne Metrics gibt es keine Grundlage für SLA-Tracking, kein Alerting und keine Möglichkeit, Latenzprobleme zu debuggen. Ein produktionsreifer Setup mit Prometheus, Grafana, Loki und Alertmanager erfordert initiales Know-how und laufende Pflege: Dashboards anpassen, Alert-Regeln verfeinern, Log-Retention konfigurieren und Cardinality-Explosionen im Prometheus-TSDB verhindern. Wer das weglässt, merkt Probleme oft erst, wenn sie sich bereits auf Endnutzer auswirken.
Secret Management: Kubernetes Secrets sind standardmässig nicht verschlüsselt. Sie werden in etcd als Base64-kodierte Werte gespeichert. Base64 ist Kodierung, keine Verschlüsselung: Wer Lesezugriff auf etcd oder entsprechende RBAC-Rechte hat, kann alle Secrets im Klartext lesen. Ein produktionsreifes Setup braucht entweder Encryption at Rest (via EncryptionConfiguration für etcd) oder einen externen Secret Store. Der External Secrets Operator liest Secrets aus externen Stores wie HashiCorp Vault oder AWS Secrets Manager und injiziert sie als native Kubernetes Secrets zur Laufzeit. Das reduziert die Angriffsfläche erheblich, braucht aber dediziertes Know-how und laufende Pflege.
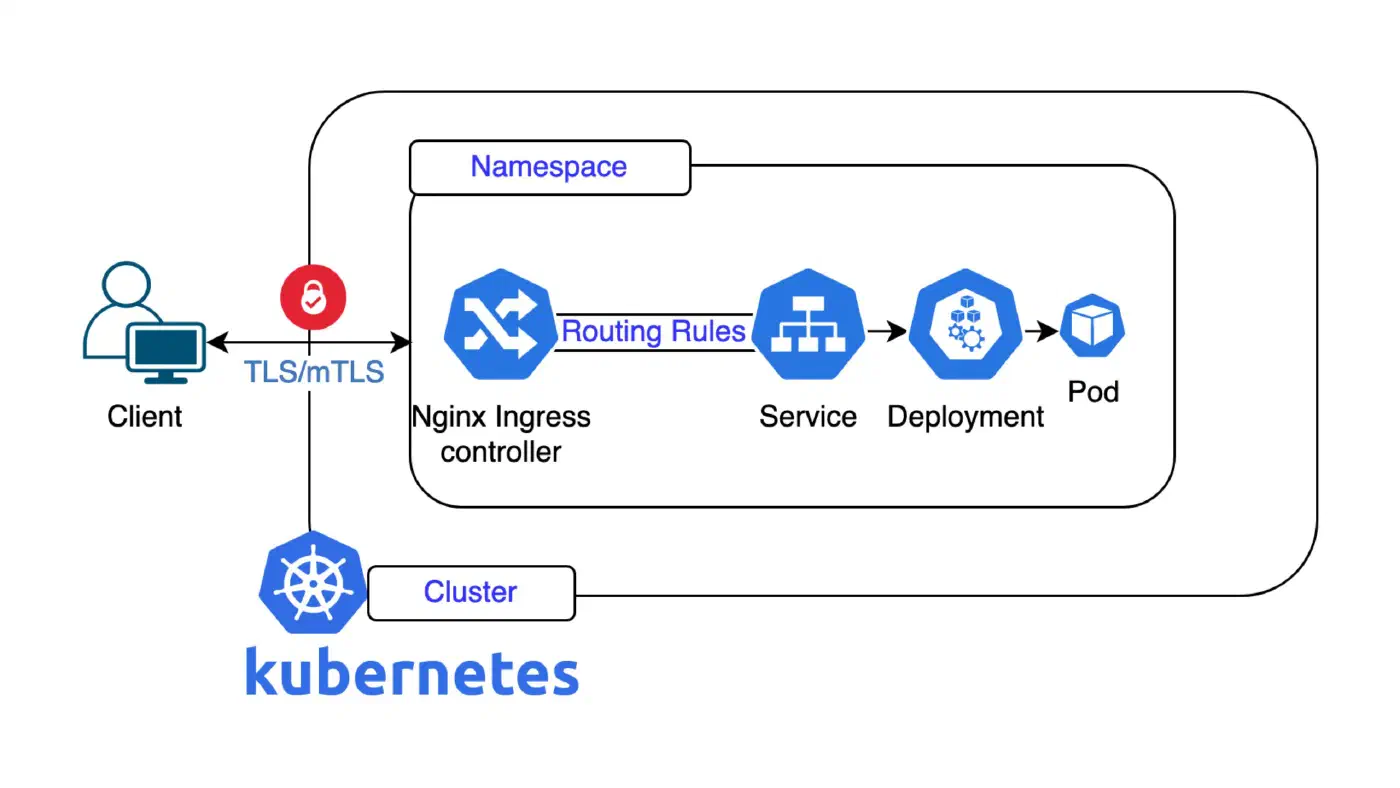
Network Policies und RBAC: In einem frisch aufgesetzten Kubernetes-Cluster kann by default jeder Pod mit jedem anderen kommunizieren, unabhängig von Namespace oder Team. Das ist praktisch im Entwicklungsumfeld, in Produktion aber ein Sicherheitsrisiko. Granulare NetworkPolicy-Ressourcen müssen explizit definiert werden, um Ingress- und Egress-Traffic zwischen Workloads einzuschränken. Dazu kommt RBAC: Wer darf welche Kubernetes-Ressourcen lesen, anlegen, löschen? Eine zu grosszügige Vergabe der ClusterAdmin-Rolle ist einer der häufigsten Sicherheitsfehler in selbst betriebenen Clustern. Beides braucht ein durchdachtes initiales Konzept und laufende Überprüfung, besonders wenn das Team wächst.
Wie eng Network-Isolation, Secret Management und Security-Patches zusammenhängen, zeigte IngressNightmare im März 2025 eindrücklich: CVE-2025-1974 (CVSS 9.8) ermöglichte unauthentifizierte Remote Code Execution (RCE) über den Admission-Webhook des Ingress-Controllers, was einem vollständigen Cluster-Takeover gleichkam, inklusive Lesezugriff auf alle Secrets in allen Namespaces. Betroffen waren über 40 % aller produktiven Kubernetes-Umgebungen weltweit. Fix: ingress-nginx v1.12.1 bzw. v1.11.5+. Der Vorfall zeigt: Wer mit dem Einspielen von Security-Patches in Verzug gerät, riskiert genau die Daten, die im Secret-Store als «sicher» gelten.
Update (März 2026): ingress-nginx wurde offiziell eingestellt, das heisst es werden keine weiteren Releases, Security-Patches oder Bug-Fixes mehr veröffentlicht. Teams, die noch ingress-nginx einsetzen, sollten die Migration dringend angehen. HAProxy (HAProxy Technologies Kubernetes Ingress Controller) ist eine aktiv gepflegte Alternative mit Gateway-API-Unterstützung. Laut eigenen Benchmarks von HAProxy Technologies erzielt er einen höheren Durchsatz und geringere Latenz als ingress-nginx.
Was das für dein Team bedeutet
Jede Stunde, die dein Team mit Kubernetes-Plattform-Ops verbringt, ist eine Stunde weniger für die Entwicklung eures Produkts. Der CNCF Annual Survey 2024 nennt fehlendes Training und interne Expertise konsistent als eine der grössten Kubernetes-Herausforderungen in Unternehmen. Für kleine und mittlere Teams ohne dediziertes Platform Engineering ist das eine ernsthafte Ressourcenfrage. CKA-zertifizierte Engineers sind teuer und auf dem Schweizer Markt schwer zu finden.
Die Alternative: Den Plattform-Ops-Aufwand auslagern, statt selbst aufzubauen.
Was ein Managed Kubernetes Service tatsächlich abdeckt
Nicht alle Managed Kubernetes Angebote sind gleich. Der Unterschied liegt darin, was tatsächlich gemanagt wird. Viele Anbieter übernehmen nur die Control Plane, der Rest bleibt beim Kunden.
Mit der Nine Kubernetes Engine (NKE) übernehmen wir den gesamten Stack:
- RKE2-basiert (CIS-gehärtet, FIPS-fähig) mit Cilium als CNI (CNCF Graduated Project)
- Automatische Cluster-Upgrades (Control Plane und Worker Nodes, ohne Version-Skipping)
- Vollständiger Observability-Stack: Prometheus, Grafana, Loki, Alertmanager (preconfigured und produktionsbereit ab Tag 1)
- GitOps mit ArgoCD
- Secret Management via External Secrets Operator
- HAProxy Kubernetes Ingress Controller (hoher Durchsatz, aktiv gepflegt, Gateway-API-Unterstützung)
- cert-manager für automatische TLS-Zertifikate
- Private Container Registry
- Automatisches Backup und Restore mit konfigurierbaren Zeitplänen
- Node-Autoscaling via KEDA (CNCF Graduated Project, event-driven, skaliert auch auf 0)
- 99.5 % Uptime SLA auf Nine-Infrastruktur (99.95 % auf Managed GKE)
Dahinter stehen CKA-zertifizierte Engineers als direkte Ansprechpersonen und kein L1-Support oder anonymes Ticketsystem.
«Dank der Zusammenarbeit mit Nine können wir uns auf das konzentrieren, was wir am besten können: Softwarelösungen für das Gesundheitswesen entwickeln. Die Infrastruktur läuft sicher und zuverlässig im Hintergrund, sodass wir unseren Kundinnen und Kunden die besten Lösungen bieten können. Mit Nine haben wir einen starken, lokalen und verlässlichen Partner an unserer Seite.»
Moritz Habegger, healthinal
Für regulierte Branchen: Schweizer Datenhoheit inklusive
NKE läuft auf Schweizer Infrastruktur. Alle Daten verbleiben in der Schweiz, ohne CLOUD Act- oder FISA-Risiko. Wir sind ISO 27001-zertifiziert seit 2013 und ISO 9001-zertifiziert; NKE ist DSGVO- und nDSG-konform. Das ist relevant für Unternehmen in regulierten Branchen wie Gesundheitswesen, Fintech oder öffentliche Hand, aber auch für alle anderen, die keine US-Jurisdiktion auf ihren Daten möchten.
Wer globale Skalierung braucht, kann auf Managed GKE (Google Kubernetes Engine, Region Zürich) wechseln, mit demselben Betriebsmodell.
Fazit
Kubernetes zu betreiben ist keine einmalige Investition. Day-2 Operations sind laufende Arbeit und sie wachsen mit dem Cluster. Die Frage ist nicht ob dieser Aufwand anfällt, sondern wer ihn trägt: dein Team oder ein spezialisierter Partner.
Wenn du wissen möchtest, was beim Einstieg in Kubernetes zu beachten ist, haben wir eine praktische Checkliste für Engineering-Teams zusammengestellt:
👉 Kubernetes-Checkliste herunterladen
Noch am Evaluieren, ob Kubernetes der richtige Schritt ist? In unserem kostenlosen einstündigen Webinar zeigen wir, wie Kubernetes in der Praxis funktioniert – mit Live-Demo und Fragerunde:
👉 Kostenlos zum Webinar anmelden
Oder direkt und unverbindlich mit unseren Expertinnen und Experten sprechen:
